理论讲解
快慢指针是一个非常经典是算法思维,常常被用来在链表中寻找循环入口。
它在实际开发中也有比较广泛的使用,例如:在垃圾回收算法(如 Mark-Sweep)中,检测对象引用链中的环可以帮助发现和处理内存泄漏问题。避免不必要的对象占用内存资源。在图算法中,检测循环可以帮助识别图中的强连通分量或检测有向图中的环。这对于解决依赖关系、任务调度和项目管理等问题至关重要。以及在网络协议栈中,可以使用类似的算法来检测数据包在网络路径中的环路。这有助于防止数据包在网络中无限循环,提高网络效率和安全性。
接下来具体讲解这个算法的思想。
存在循环结的链表的模型如下
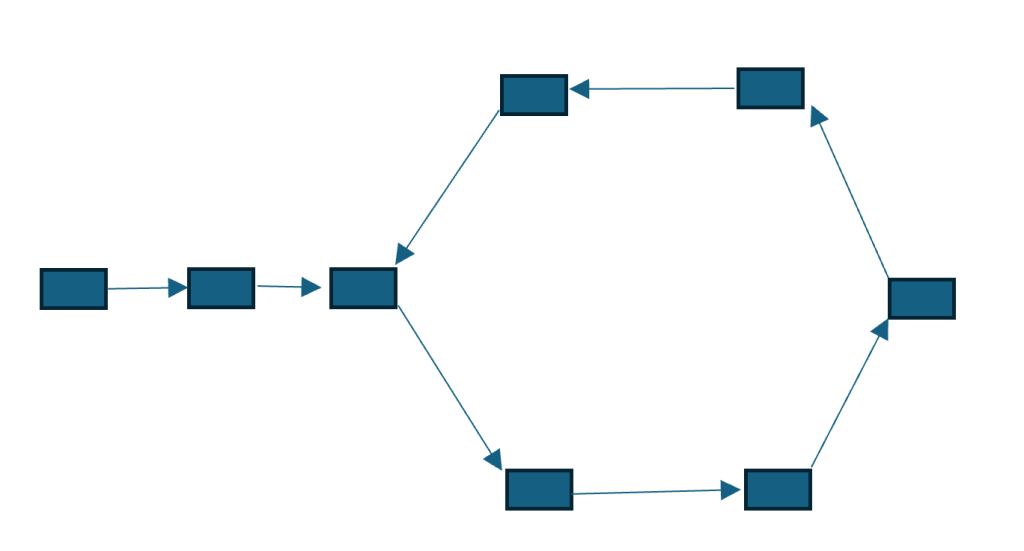
通常的设置是,快指针的速度是慢指针的两倍。
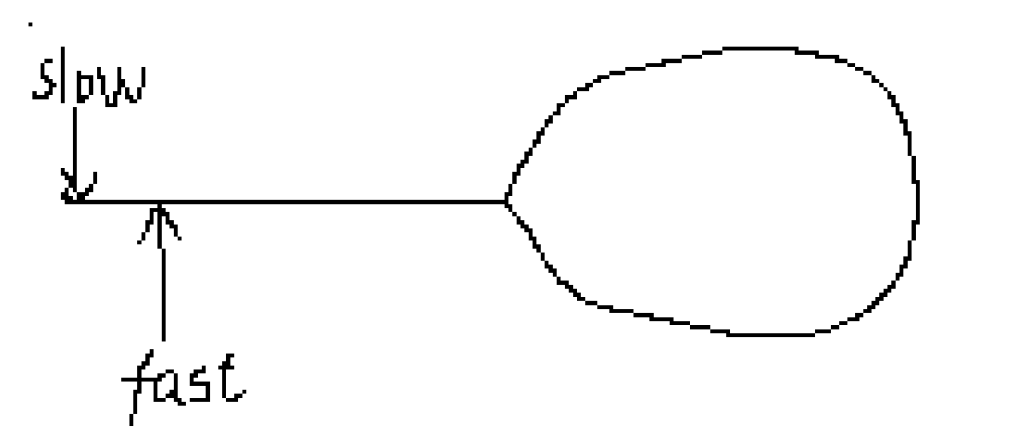
通过简单的逻辑思考,可以得出一个结论:当快指针进入循环节后,总会被慢指针追上,或者说是快指针转了至少1圈后会超过慢指针。但是这个只是一个通过朴素的思考得出的结论,实际上还存在更加底层的结论——慢指针一定会在第一圈中被快指针超越。
接下来我将推导出这个结论。先看看快指针超越慢指针的情况:
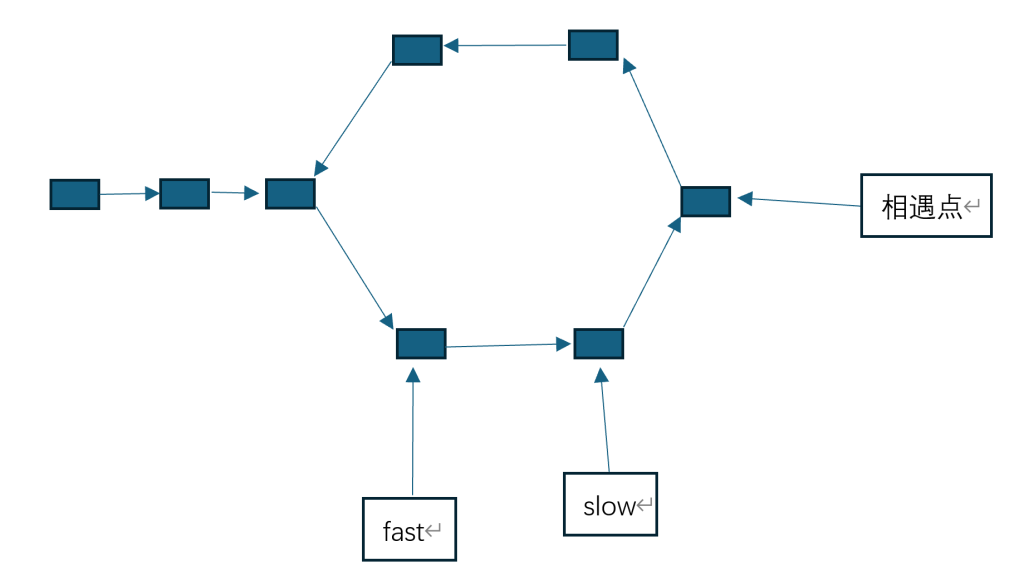
当快指针从后面追上慢指针的时候,它们会在出现途中的相邻情况,然后在相遇点相遇。还有另外一种不相邻的情况:
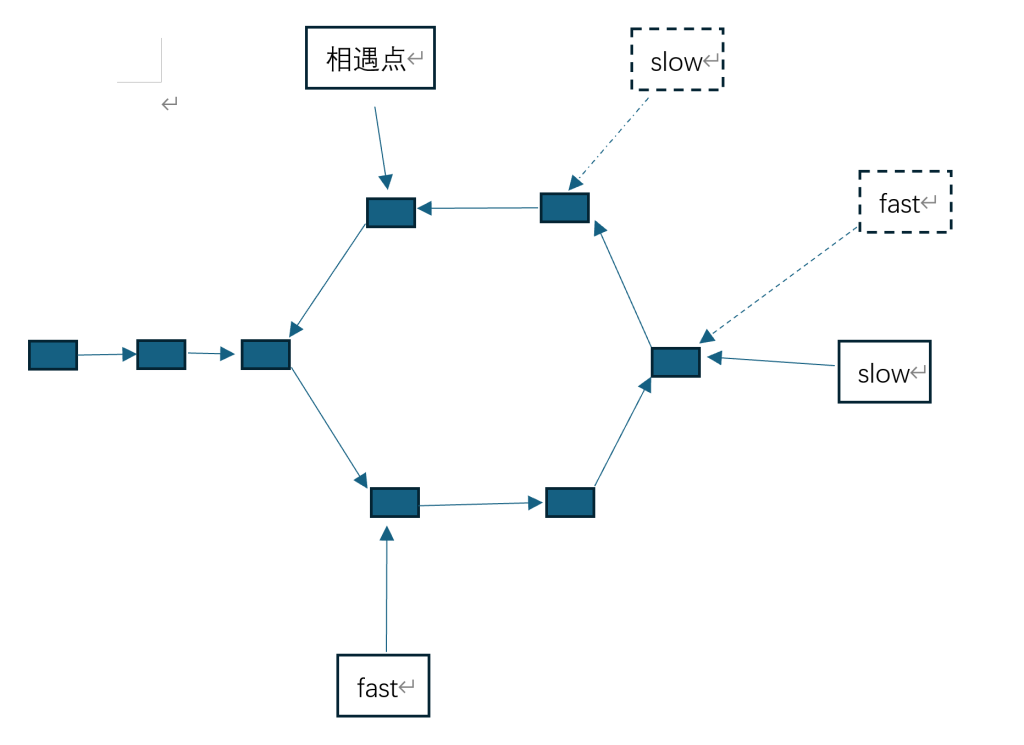
如果是这种不相邻的情况,它也会经过一轮转换后成为相邻情况。
综合两种情况,可以得出一个结论, 只要快指针超过了慢指针,则一定发生了相遇。那么为什么快指针一定会在第一圈中与慢指针相遇呢?
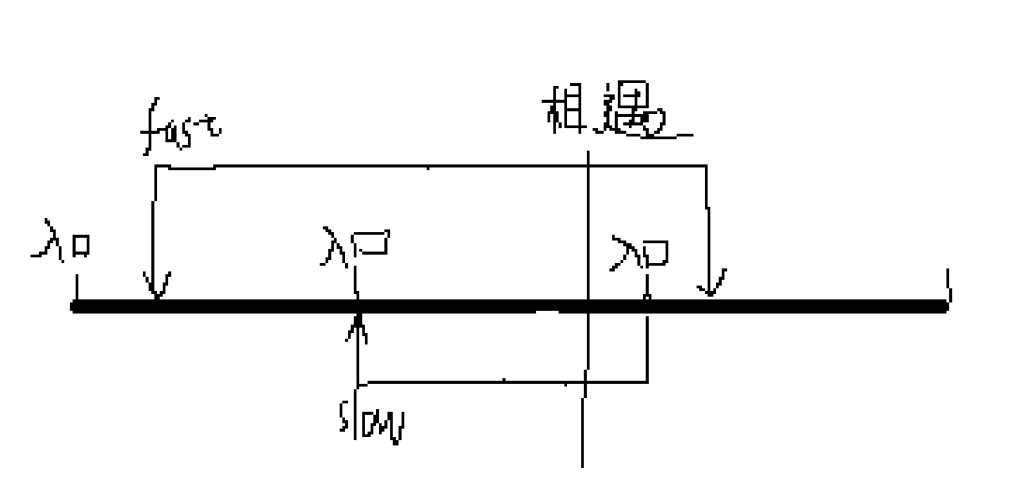
将时间轴铺开,在慢指针进入到了循环入口的时候,快指针开始追击,而快指针的速度是慢指针的两倍,所以快指针在从和慢指针进入循环节的瞬间触发到停下来,会完成两个循环,也就是说,慢指针一圈完成的时候,快指针已经在第二圈走了一部分了,由此可以推断,快指针一定在慢指针进入的第一圈中出现了超越行为。之前证明了结论“只要快指针超过了慢指针,则一定发生了相遇”,所以可以推断出,快指针在慢指针旋转的第一圈中出现了相遇。
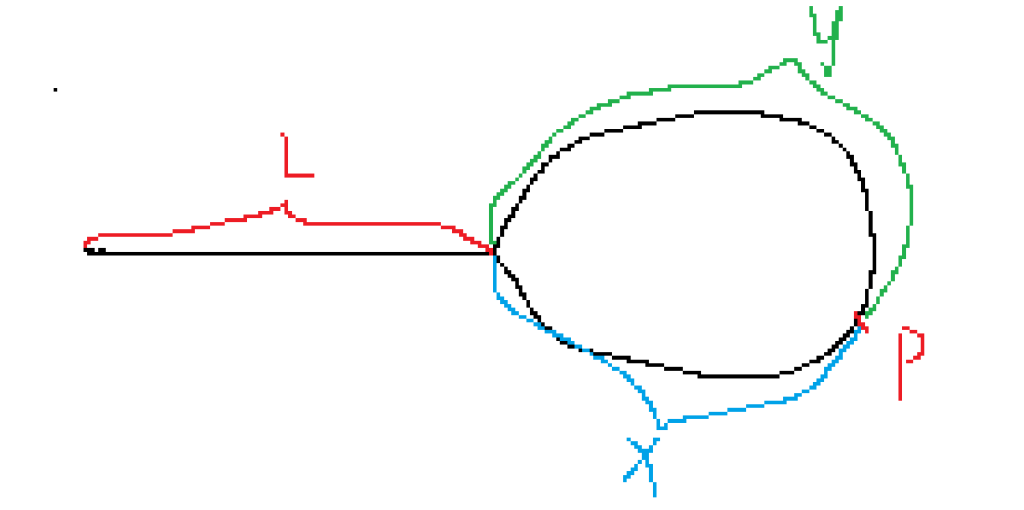
假设循环节是逆时针旋转,p点为相遇点,那么就可以将整个链表划分为3段。
根据快指针走的距离长度是慢指针走的距离长度的两倍,可以得出一个等式:
2(L + X) = (L + X) + n(X + Y)
这个等式的含义是,快指针等式的含义为:慢指针走的距离加上还有自己由于跨度大多走了几个循环。
想知道入口的位置,那么只需要计算出L的长度便可,那么等式就可以转化一下:
L + X = n(X + Y)
L = n(X + Y) – X
L = (n-1)(X + Y) + Y
那么就可以通过表达式看几何意义,首先证明过快指针追上慢指针至少要循环一圈那么n就一定≥1,所以n-1一定大于等于0。
此外在观察表达式会发现一个特别有趣的点:(n-1)(X + Y)几何意义是绕着循环节转圈,那么在对于最终移动长度没有任何影响,可以看作是原地踏步,所以(n-1)(X + Y) + Y 的等效距离就是Y 。所以在等效距离上,这个表达式可以写作:L = Y
而此外Y的含义是相遇点P到循环入口的距离,而L的含义是链表起点到入口的距离,这就推导出了一个及其震撼的结论:
如果一个指针从起始节点一直往前走,另一个指针从P点开始往前走,那么两个指针会在入口相遇。
实战
数组a[N],存放了1至N-1个数,其中某个数重复了一次。写一个函数,尽快找出被重复的数字并返回之。
int do_dup(inta[],intN){
}
这一题就是典型的双指针寻找循环入口的题目。
由题目可得,数组的元素本质上可以看作下一个元素的下标,于是所有的数组就以链表的思路联系了起来。
参考代码:
#include <stdio.h>
int do_dup(int a[], int N) {
int slow = a[0];
int fast = a[0];
// 阶段 1:找到循环中的相遇点
do {
slow = a[slow];
fast = a[a[fast]];
} while (slow != fast);
putchar(10);
// 阶段 2:找到循环的起点
slow = a[0];
while (slow != fast) {
slow = a[slow];
fast = a[fast];
}
return slow;
}
int main() {
int a[] = { 1, 3,11, 4 ,2 ,7, 8 , 2, 10,6 ,5, 9};
int N = sizeof(a) / sizeof(a[0]);
int duplicate = do_dup(a, N);
printf("重复的数字是: %d\n", duplicate);
return 0;
}
