Linux的发展历史
操作系统的五大基本功能:文件管理、内存管理、进程管理、设备管理、网络管理
肯·汤普森、丹尼斯·里奇、理查德·斯托曼和林纳斯·托瓦兹是 Linux 发展历史上四位最重要的人物。他们分别代表了 Linux 发展的三个阶段:
- 肯·汤普森和丹尼斯·里奇代表了 Linux 的起源。他们是 Unix 操作系统的创始人,Linux 内核的设计和实现都受到了 Unix 的影响。
- 理查德·斯托曼代表了 Linux 的发展。他发起的 GNU 计划旨在创建一个完全免费和开放源代码的操作系统。Linux 内核是 GNU 计划的重要组成部分。
- 林纳斯·托瓦兹代表了 Linux 的成熟。他是 Linux 内核的主要开发者,他将 Linux 内核从一个小小的项目发展成为今天的巨型操作系统。
肯·汤普森和丹尼斯·里奇
肯·汤普森和丹尼斯·里奇是美国计算机科学家,他们在贝尔实验室工作期间开发了 Unix 操作系统。Unix 是世界上第一个成功的操作系统,它对后世的操作系统产生了深远的影响。
1969 年,肯·汤普森在贝尔实验室开发了 B 语言,这是 Unix 的第一个编程语言。1973 年,肯·汤普森和丹尼斯·里奇一起用 C 语言重写了 Unix 内核。C 语言是 Unix 的标准编程语言,它也成为了世界上最流行的编程语言之一。
理查德·斯托曼
理查德·斯托曼是美国计算机科学家,他是自由软件运动的创始人。1983 年,他发起的 GNU 计划旨在创建一个完全免费和开放源代码的操作系统。
GNU 计划的目标是开发一个与 Unix 兼容的操作系统,它包括了内核、工具链和应用程序等。GNU 计划取得了巨大的成功,它为 Linux 的发展奠定了基础。
林纳斯·托瓦兹
林纳斯·托瓦兹是芬兰计算机科学家,他是 Linux 内核的主要开发者。1991 年,他开始开发 Linux 内核,当时他只有 21 岁。
Linux 内核最初只是一个用来访问大学大型 Unix 服务器的虚拟终端。后来,林纳斯·托瓦兹将 Linux 内核发布到 Usenet 上,并开始征求其他程序员的帮助。
在众多志愿者的贡献下,Linux 内核迅速发展。1992 年,Linux 内核首次支持多处理器。1993 年,Linux 内核首次支持图形界面。1994 年,Linux 内核首次支持网络。
随着 Linux 内核的不断发展,越来越多的程序员开始使用 Linux。目前,Linux 已经成为世界上最流行的操作系统之一。它广泛应用于服务器、桌面、移动设备、嵌入式设备等领域。
Linux分支
Red Hat 分支
Red Hat 分支由 Red Hat 公司开发,以其稳定性和企业级支持而闻名。Red Hat 分支的代表发行版包括 Red Hat Enterprise Linux(RHEL)、CentOS、Scientific Linux 等。
Red Hat 分支的特点包括:
- 使用 RPM 包管理器
- 提供稳定的发布版本
- 提供企业级支持
Debian 分支
Debian 分支由 Debian 社区开发,以其自由和开源而闻名。Debian 分支的代表发行版包括 Debian、Ubuntu、Linux Mint 等。
Debian 分支的特点包括:
- 使用 apt 包管理器
- 提供稳定的发布版本
- 提供免费支持
Linux安装和vm
vm网络配置的四种模式:
桥接模式:
ubuntu会分配一个单独的IP,并可以使用该ip访问外部网络,ubuntu通过虚拟网络适配器与宿主机的网络适配器链接,从而实现与外部网络进行访问。
NAT模式:
ubuntu和宿主机共用一个ip访问外部网络,ubuntu发送请求给物理主机,物理主机访问外部网络,并返回给ubuntu,本质上是宿主机和虚拟机构建了一个局域网。
仅主机模式:
ubuntu只能和宿主机通信,不能访问外部网络
自定义模式:
只能在同一宿主机的几个虚拟机之间通信,并无法访问宿主机和外部网络
终端
在Linux中,终端是用户与计算机进行交互的界面。它可以是物理的设备(如键盘和显示器)或虚拟的终端窗口。用户可以通过终端输入命令并查看计算机的输出。在图形用户界面(GUI)中,终端通常是模拟的命令行窗口。
终端的打开方式
1.鼠标点击终端图标
2.在文件系统中鼠标右键,在终端中打开
3.使用快捷方式键:
“ctrl+alt+t” 打开一个新的终端
“ctrl+shift+n” 打开一个相同路径的终端(在已经打开的终端中使用)
“ctrl+shitf+t” 打开一个相同路径的终端,且用分屏的方式显示(在已经打开的终端中使用)
终端上字符的含义
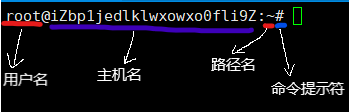
命令提示符会有两种状态——#超级用户 $普通用户
终端的基本控制
终端字体的调整
终端字体放大: “ ctrl+shift+’+‘ ”
终端字体缩小:“ ctrl+ ‘-‘ “
终端内容的清屏
命令 “clear”
快捷键 “ctrl+l”
关闭终端
命令 “exit”
快捷键1 “ctrl+d”
快捷键2 “alt+f4”
终端与shell命令
shell(贝壳):是Linux内核外层保护工具,负责和内核之间进行交互是一个命令行解析器,它使用户和操作系统之间进行交互
shell历史
shell的发展史上存在很多版本的shell,以下是四个有代表性的版本:
sh (Bourne Shell) 是最早的标准 shell,由 AT&T 公司的 Steve Bourne 开发。其他 shell 在其基础上进行了改进和扩展
csh (C Shell) 是由柏克莱大学的 Bill Joy 设计的,语法类似于 C 语言。它在一些方面改进了 Bourne shell,但也有一些局限性。
ksh (Korn Shell) 是在 Bourne shell 和 C shell 的基础上开发而来的。它融合了两者的优点,被广泛用于 UNIX 系统。
bash (Bourne Again Shell) 是由 GNU 组织开发的,保持了对 sh shell 的兼容性。它是各种 Linux 发行版默认配置的 shell。bash 扩展了一些命令和参数,但在大多数情况下与 sh 的区别不大。
注意:这四个版本存在迭代的关系,而bash是当前Ubuntu默认命令行解析器。除此之外,shell还存在zsh、dish、dash等版本
命令的组成
指令 + 选项 + 参数
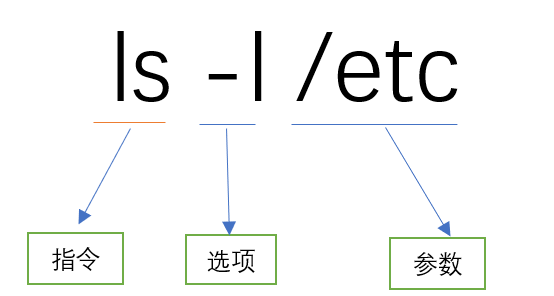
指令不能省略,选项和参数可以省略,并且可有同时拥有多个选项和参数,参数和选项可以交换位置,指令不可以交换位置。
常用的几个基本命令
查询历史命令:history / 上下键
复制命令: ”ctrl + shift + c “ 粘贴命令: ” Ctrl + shift + v “
关机命令 :
”shutdown -h now“ 关机 补充:”shutdown 12:00“在12点时关机 ,”shutdown +5“ 五分钟之后关机 。
”shutdown -r now“ 重启 补充:”shutdown -r 12:00“ 12点重启。
”shutdown -c“ 取消操作
重启命令:”reboot“ 立即重启
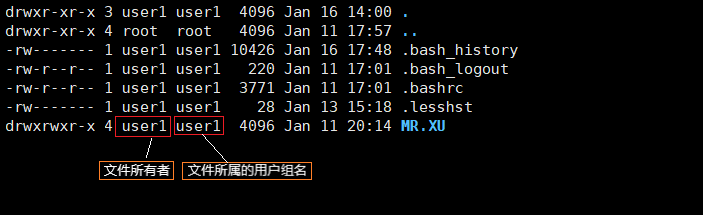
Linux与文件
核心思想:Linux系统的一切都是文件,不以文件的后缀名作为文件类型的区分。
解释:
在 Linux 系统中,任何东西都可以通过文件的方式访问和管理,即使它们不是传统意义上的文件。例如,硬件设备、进程、套接字等都抽象成文件,使用统一的用户接口。
传统意义上的文件,通常是指存储在磁盘或其他存储设备上的数据。这些文件通常具有后缀名,用于标识文件的类型。例如,文本文件的后缀名通常是 .txt,二进制文件的后缀名通常是 .exe。
在 Linux 系统中,文件的后缀名不再具有文件类型的区分作用。文件的类型由文件系统中的文件属性决定。例如,普通文件的文件属性中有一个叫做“类型”的属性,其值可以是“普通文件”、“目录”、“符号链接”等。
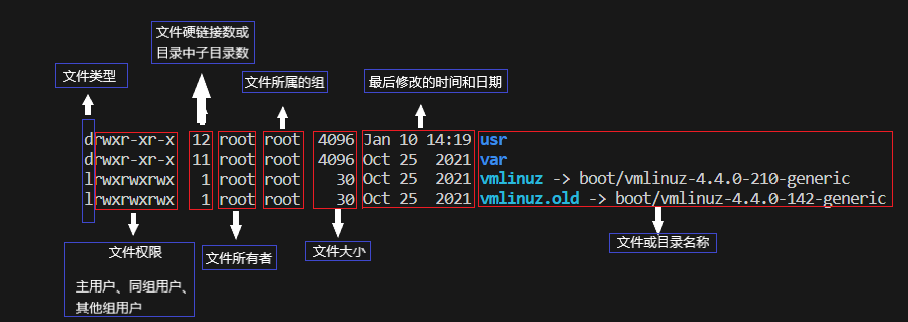
Linux系统中的7种文件类型
1.普通文件:最为常见的文件类型,包括文本文件、二进制文件、图像文件等,在ls -l命令中,普通文件以符号-(Regular file)开头
2.目录文件:是一种特殊的文件类型,也称为目录,用于存储其他文件和目录,在ls -l命令中,文件以符号d(Directory file)开头
3.链接文件:链接文件是指向另一个文件的文件,也称为软链接,符号链接文件并不占用磁盘空间,它只存储目标文件或目录的路径,在ls -l命令中,文件以符号l(Link file)开头
4.命名管道文件:命名管道文件是一种特殊的文件类型,用于进程间通信,管道文件是内存中的一个区域,用于进程间传递数据,在ls -l命令中,文件以符号p(Named pipe file)开头
5.块设备文件:块设备文件是指向块设备的文件,如硬盘、光驱等,块设备文件只能读写固定大小的数据块,在ls -l命令中,文件以符号b(Block device file)开头
6.字符设备文件:字符设备文件是指向字符设备的文件,比如键盘、鼠标、终端等,字符设备文件可以直接读取数据,在ls -l命令中,文件以符号c(Character device file)开头
7.套接字文件:套接字文件是一种特殊的文件类型,用于网络通信(网卡),在ls -l命令中,文件以符号s(Socket file)开头
其中,文件、目录、符号链接三种类型占用存储空间;另外四种(套接字、块设备、字符设备、管道)是伪文件,不占用磁盘空间。
目录文件
目录结构采用树型结构,所有的目录都属于根目录,其表示符号为反斜杠”/“,补充:如”/a/b“中,只有第一个斜杠表示根目录,第二个表示分隔符。
文件详细图
passwd文件
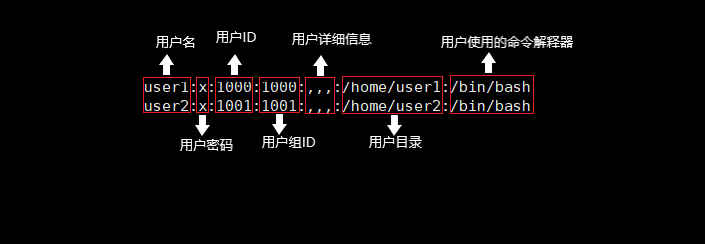
常见的一级子目录
/bin(binaries-二进制文件):主要存放Linux命令,目录包含了系统启动时需要使用的核心命令和程序,例如cd、ls
/boot(Bootloader files):存放启动系统所需的文件,例如 GRUB 引导程序和 Linux 内核等。
/dev(devices-设备):存放的是Linux所有的设备文件,例如/dev/input/event0,/dev/input/mouse0
/etc(et cetera-省略):Linux系统配置文件,用于配置系统的各种参数
/home:包含用户的主目录,用于存储用户的个人文件
/lib(library-库):动态库,包含了系统库文件,用于支持程序的运行
/mnt(mount-挂载):用于挂载其他文件系统
/media:挂载可移动设备(例如 USB、CD-ROM 等)的目录。
/opt(Optional or third-party software):存放第三方软件的安装目录,例如 Oracle 数据库等。
/proc(Process information and kernel configuration files):虚拟文件系统,存放系统内核和进程信息。
/root:超级用户的主目录
/sbin(System binaries for system administration tasks):存放系统管理员使用的系统命令,例如 ifconfig、fdisk 等。
/srv(Data for services provided by the system):存放本地服务的数据目录,例如 HTTP 服务器的网页文件等。
/sys(Virtual file system for kernel information):虚拟文件系统,存放系统硬件信息。
/tmp(Temporary files):存放临时文件的目录,例如程序运行时的临时文件等。
/user(User home directories):存放用户数据的目录,例如用户文档、图片等。
/var(Variable data, such as logs, databases, and websites):存放系统运行时产生的文件,例如日志文件、缓存文件等。
常用的目录命令
cd
cd是change directory的缩写,该命令的作用是:切换目录
命令格式: cd 目标路径
常用命令:cd ~ (进入用户主目录) cd . (进入当前路径) cd .. (进入上一级目录) cd – (回到上一次操作路径)
pwd
pwd是Print Working Directory的缩写,该命令的作用是:打印当前路径的绝对路径位置
命令格式:pwd
mkdir
作用:创建新目录
格式:mkdir 目录名
创建多个目录:mkdir 目录名 目录名
选项:
-p:创建多级目录。 如mkdir -p a/b/c 在当前目录创建a,在a中创建b,在b中创建c。
-m:指定新建目录的权限,例如 mkdir -m 666 dir 创建一个所有用户可读可写不可执行的目录文件dir
rmdir
作用:删除目录(只能删除空目录)
格式:rmdir 目标路径
选项:-p 同时删除多级目录,例如:rmdir -p a/b/c,注意必须为空
ls
作用:显示目录内容
格式:
ls 目标路径(查看单独目录)
ls 目标路径1 目标路径2 目标路径3(查看多个目录)
选项:
-a:显示所有文件,包括隐藏文件
-l:显示详细信息
-i:显示文件编号
-h:显示文件大小,对于文件的大小会自动换算成合适的单位。
链接文件
1、硬链接(只能对文件操作,不能链接目录)
命令: ln 源文件 生成的目标文件名
补充:硬链接相当于给文件取别名,其inode号和源文件也相同。由于物理实现是对同一个物理空间取了多个名称,所以想删除这个空间时,必须要删除所有对其进行硬链接过的文件。
2、软链接(既可以对文件操作,也可以对目录操作)
命令: ln -s 源文件 生成的目标文件名
补充:软链接的类型是一个链接文件,其inode号与源文件不相同。其本质上是记录了源文件的位置,打开之后将会取该位置存放的信息,类似与c语言中的指针。如果源文件被删除,则会无法打开文件。
注意:创建软链接时,建议使用绝对路径,否则会出现链接文件移动至其他目录后,会出现链接文件无法使用的情况,因为它会因为相对路径改变而找不到源文件。
文件的权限
权限类型
r:读取权限(read) w:写入权限(write) x:执行权限(execute) -:没有对应权限(none)
权限修改
1、使用 chmod 通过+/-的方式修改权限
chmod命令是Change Mode缩写,其作用是:更改文件权限
通过使用ls -al命令可以查看文件的权限
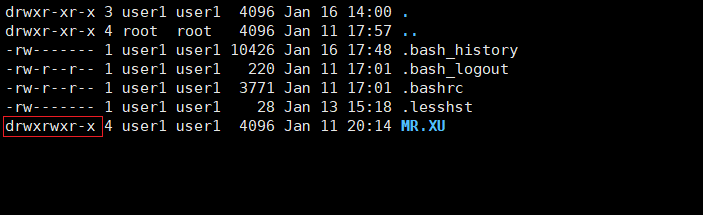
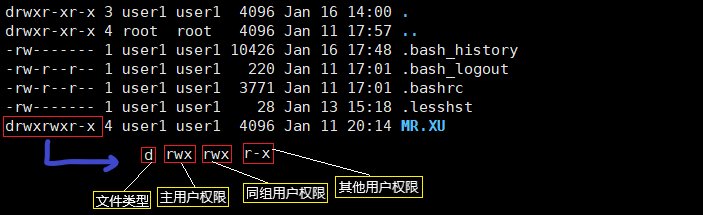
u:主用户(user) g:同组用户(group) o:其他组用户(others) a:所有用户(all users)
例如: chmod u+x 1.txt 为主用户赋予可执行权限。
chmod g-w 1.txt 删除同组用户写入权限。
chmod ug+rw 1.txt 赋予主用户和同组用户读取和写入权限
2、通过绝对权限的方式修改
命令格式:chmod (权限八进制) 文件名
权限八进制:
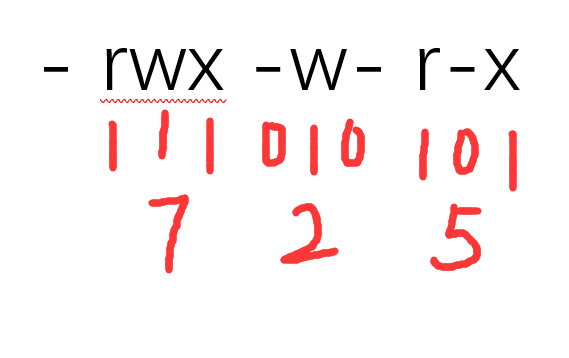
命令为 chmod 725 1.txt 或者chmod 0725 1.txt(这个0是八进制的意思)
文件属主和属组的修改
命令:chown
格式1:
chown 所有者名:组名 文件名 ——文件所有者修改、组名也修改

命令结果:

可以清晰地看到,无论是文件所有者还是文件所属的组,都已经被修改成了root用户
格式2:
chown :组名 文件名 ——文件所有者不变、组名修改

命令结果:

可以清晰地看到,文件所有者没有变,但是文件所属的组改变了
格式3:
chown 所有者名 文件名 ——文件所有者改变、组名不变

命令结果:

可以清晰地看到,文件所有者变了,但是文件所属的组没有变
格式4:
chown 所有者名: 文件名 ——文件所有者改变、组名跟随所有者所在的组改变

命令结果:

可以清晰地看到,无论是文件所有者还是文件所属的组,都已经被修改成了root用户
根据观察,我们总结出来了一个需要注意的地方:
如果只想修改文件所有者,千万要注意是否存在:号,如果加了冒号则会连同后面的文件所属组一同改变
权限掩码
系统默认的权限掩码为002
新建文件的权限 = 满权限(666) – 权限掩码
新建目录的权限 = 满权限 (777)- 权限掩码
新建文件的权限:664 (110 110 100 即主用户可读-可写-不可执行,用户组可读-可写-不可执行,其他用户可读-不可写-不可执行)
新建目录的权限:775 (111 111 101即主用户可读-可写-可执行,用户组可读-可写-可执行,其他用户可读-不可写-可执行 )
满权限由操作系统决定,文件权限默认满权限为666,目录权限默认满权限为777
查看权限掩码命令:umask

其中第一个0代表的是八进制,002是权限掩码
设置权限掩码:umask 权限掩码 (注意,这是临时修改,如果终端关闭,权限掩码将恢复到默认)

可以看到权限掩码确实修改成了0004,当然也可以输入004,这个没有影响。
但是重新启动一个终端后,会发现权限掩码会恢复到默认的0002:
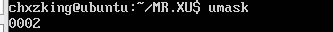
注意:对于文件权限权限掩码最好不要设置为奇数,因为系统会修正权限掩码
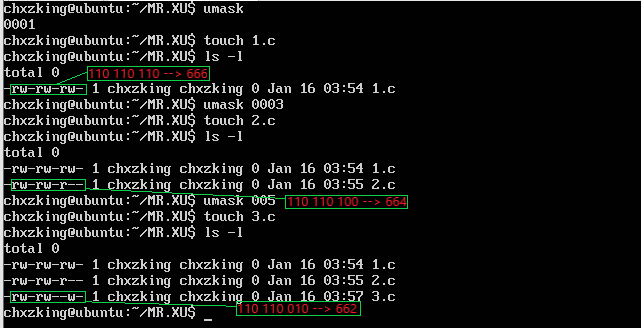
在这个例子中,我们看到预期的1.c的665权限变为了666,2.c预期权限为663变为了664,3.c预期权限661变为了662 。所以,当权限掩码被设定为奇数时,最终生成的文件权限 = 满权限-权限掩码+1
常用的文件命令
touch
作用:创建一个文件。(如果文件不存在创建一个新文件,如果文件存在,则修改一个文件的时间戳)
用法:touch 文件名
cat
作用:显示文件的内容
用法:
cat 文件名
cat 目标文件1 > 目标文件2 【“>”重定向符号,整个命令的作用是将目标文件1中的内容输出到目标文件2中,注意是覆盖之前的文件。“<”同理,不过是将重定向方向反过来】
cat 目标文件1 >> 目标文件2 【“>>”重定向符号,整个命令的作用是将目标文件1中的内容输出到目标文件2中,注意是在文件2末尾追加。“<<”同理,不过是将重定向方向反过来】
补充:重定向符号并不是cat的专属,而是在其他有输出显示的命令中都可以使用
cat > 目标文件(等待用户输入,并将输入信息写入目标文件,ctrl+c结束操作。注意:别忘了加回车)
cat >> 目标文件(等待用户输入,并将输入信息写入目标文件,ctrl+c结束操作。注意:别忘了加回车)
选项:
-E (show-ends) 表示行末尾加上$符号
-n (number) 显示行号
mv
作用:移动或重命名
用法:
移动用法
mv 文件名 目录(将文件移动到目录中,注意:目录必须存在,否则会将文件重命名为输入的目录名。)
mv 目录1 目录2 (将目录1移动到目录2中,注意:目录2必须存在,否则会被判定为更改目录的名字)
重命名用法
mv 文件1 文件2(将文件1重命名为文件2,注意:若文件2存在,文件1会直接覆盖文件2的内容)
mv 目录1 目录2(将目录1重命名为目录2,注意:目录2必须不存在,否则会将目录1移动到目录2中)
选项:
-f (force) 强制模式
-v (verbose) 提示移动的步骤
-i(interactive) 询问模式
rm
作用:删除
-r 目标目录 这个选项的作用是删除目录文件
cp
作用:复制文件或者目录
用法:
cp 文件1 文件2 (若文件2存在,文件2信息被文件1覆盖。若不存在,会创建一个文件2)
cp 文件 目录(将文件复制到指定目录,注意:必须存在目录,否则系统会将目录错认为一个文件名,并创建)
cp -r 目录1 目录2(目录1及其子文件全部复制到目录2中)
选项:
-i 询问方式
more
作用:分屏查看文件内容(按空格下一页、ctrl+f往下、 ctrl+b往上)
选项 -n 每次显示n行
例如: more -10 1.c 让1.c中的内容每次显示10行
less
作用:分屏查看文件内容
选项 -M 百分比显示
head
作用:显示文件头部内容(默认显示10行)
选项 -n 显示头部n行,例如:head -5 1.c 显示1.c文件中的前五行
tail
作用:显示文件末尾内容
选项 -n 显示尾部n行道内容 ,例如 tail -5 1.c显示文件1.c中的后五行
split
作用:文件分割命令
选项:
-b (bytes 字节) 1000 1K 1M 1G:指定分割后的文件的大小
-a 后缀序号的位数
-d 跟文件的名字,指定生成的文件名
例子:split 文件1.txt -b 5M -a 1 -d 文件片段.txt(将文件1.txt分为5M一个都小文件,小文件的序列位数只有一个)
wc
作用:计数
用法:wc 文件名
返回结果:行数 单词个数 字符总数 文件名
grep
作用:搜索文件中的字符串
用法:
grep "字符串" 文件名 寻找含有字符串的字符串
grep "^字符串" 文件名 寻找以该字符串开头的字符串
grep "字符串$" 文件名 寻找以该字符串结尾的字符串
grep "^字符串$" 文件名 寻找只有该字符串的字符串
选项:
-n 显示行号
-i 忽略大小写
补充:
通过 []进行多个匹配,注意:每个[]代表一个字符,比如grep "s[ae]" 1.c代表sa开头或者se开头,比如:

[^]反向选择,假设搜索一个含有h的字符串,但是不想这个h上一个字符是a,就可以这样使用:grep "[^a]h" 1.c 多个字符可以写成这种形式:[^0-9a-z],这会一次性排除0,1,2……9和a,b……z
通常*(重复零个或者多个前一个字符)和.(任意一个字节)具有特殊含义,所以如果希望选中名字中存在.的字符需要使用\.来去掉其特殊含义。
推荐在grep后面的字符使用“”号或者‘’号引起来,因为不写符号会出现无法转义的情况,举例:
假设我有a.c ea.c axc 三个文件,ls | grep a.c会显示三个文件,如果本意是显示.而非任意符号,那么按理来说要使用\.来转义,但是如果没有写符号 ls | grep a\.c,那么输出结果依旧是三个文件,只有使用符号ls | grep "a\.c"才能让转义符号\生效,此时的输出是a.c和ea.c
cut
作用:按列去查看文件
用法: cut -d ‘分隔符’ -f 目标列 文件名
-d (delimiter 分隔符)指定使用分隔符(文件里面必须存在这个分隔符)
-f (fields 字段) 指定查看哪一列
连续的列可以使用-,比如1-4就是1到4列
cmp
作用:比较两个文件内容 ,文件相同没有输出,如果不同输出第一个不同的位置
用法 cmp 文件1 文件2
find
作用:以递归的方式查找指定文件
用法: find 目标目录 查找规则 目标文件
选项:
-name 按照文件名查找
-size 按照大小查找(c,k,M,G,T——字节、KB、MB、GB、TB)+5M代表大于5M的文件,-3M代表小于3M的文件,不写符号代表等于
-user 按照文件属主查找
-group 按照文件属组查找
-perm 按照文件绝对权限查找(八进制参考3.6.2.1)
-and 条件取与,例如 find ./ -user zhangsan -and -name a.c
-or 条件取或 ,例如 find ./ -name root -or -size +1k
-not 条件取反,,例如 find ./ -not -name "*.c" 查询不以*.c结尾的文件
vim编辑器
vi是Linux中最基本的编辑器。
vim的三种工作模式
命令行模式:vi编辑器打开一个文件的时候,默认为命令模式。可以通过命令进行控制光标的定位,复制,粘贴,查找等模式
插入模式:只有在该模式下,才能输入字符
底行模式:通过命令来退出、保存等
不同工作模式之间的切换
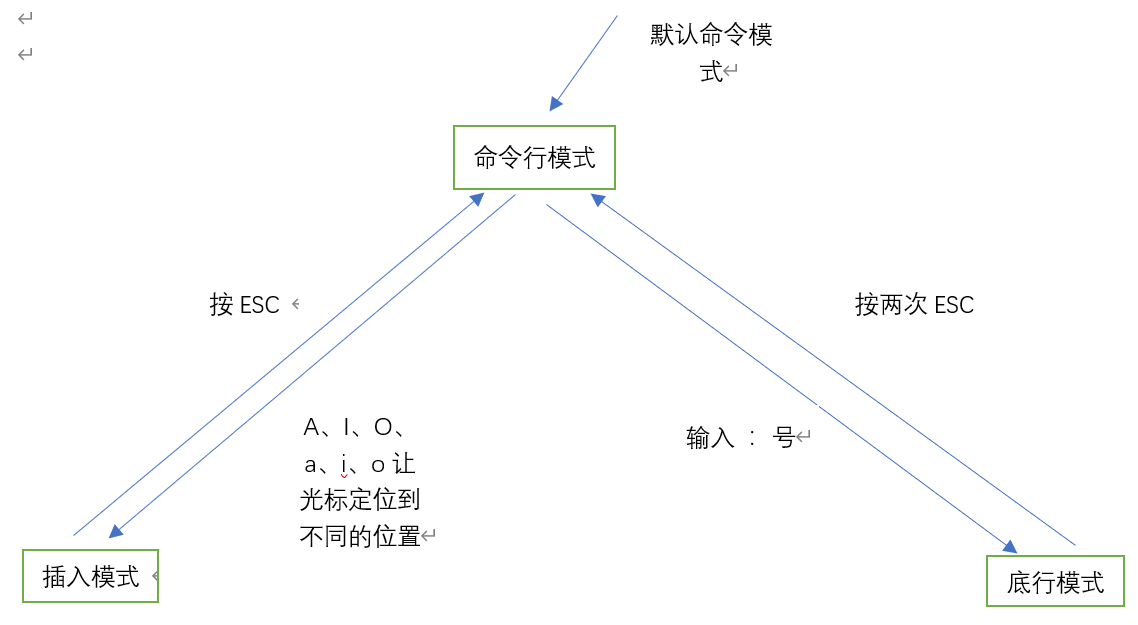
A 在当前行的行末插入 a在光标的下一个位置插入
I 在当前行的行首位置插入 i 在光标当前位置插入
O 在当前行和上一行之间插入新的一行 o 在当前行和下一行之间插入新的一行,相当于使用了一个回车
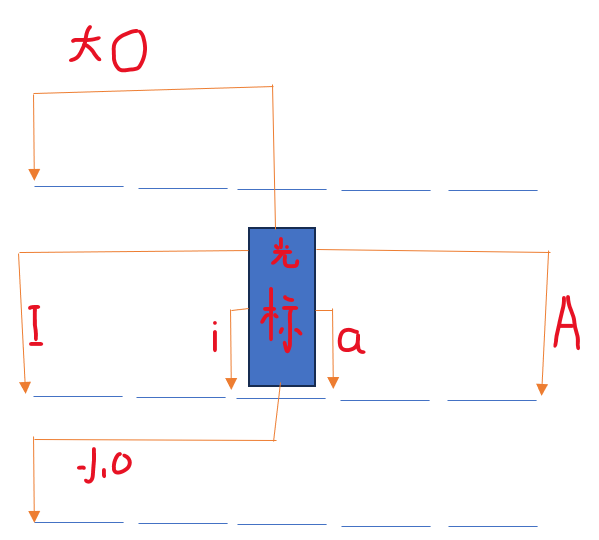
不同模式下的命令
命令模式下常用的命令
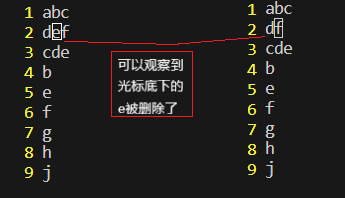
yy 作用:复制光标所在的一行(yank简写)

p 作用:在当前行的下一行粘贴
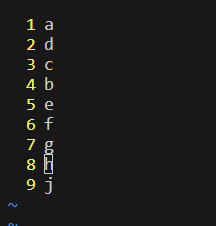
如果我在第八行使用p命令,则会出现以下效果:
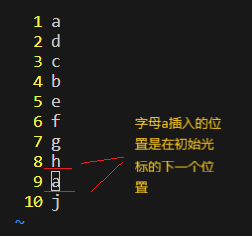
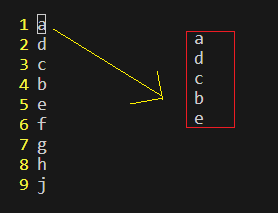
nyy 作用:复制光标开始的向后的n行
例如:我在第一行使用5yy,那么他会复制从a开始到5行
dd 作用:剪切
ndd 作用剪切n行
u 撤销
gg 定位到文件第一行
G 光标定位到文件最后一行
nG 或者 ngg 光标定位到第n行
x 删除光标前面对应的一个字符
底行模式下常用的命令
w 保存
q 退出
wq 或者 x 或者快捷键 shift+z+z 保存退出
!强制执行
wqa 保存并退出所有的文件
vsp 文件名 以左右分屏打开一个文件
sp 文件名 上下分屏的方式打开另外一个文件
/查找的内容 查找指定内容(n跳转下一处被查找到的内容,N上一处被查找到的内容)
noh 取消高亮显示
set number 显示行号 缩写 set nu
no set number 隐藏行号 缩写 set nonu
s/目标字符/所替换的字符 例如:s/a/b 将光标所在的行的第一个a替换成b
起始行号,结束行号s/目标字符/所替换字符 例如 1,5s/a/b 将1到5行的每行第一处a替换为b
起始行号,结束行号s/目标字符/所替换字符/g 例如 1,5s/a/b/g 将1到5行中所有的a都替换成b
%s/目标字符/所替换字符/g 将文件中所有的目标字符都替换为希望替换的字符。例如%s/a/b/g 将所有的a都替换成b
打包和压缩
Linux中有三种压缩后缀:.gz .bz2 .xz 压缩命令分别是 gzip bzip2 xz 它们的压缩速度逐渐降低,压缩率逐渐增高
压缩对象是文件,压缩目录需要先进行打包。
解压和压缩
gzip 文件名 (生成文件名.gz) 解压 gunzip 文件名.gz
bzip2 文件名 (生成文件名.bz2)解压 bunzip2 文件名.bz2
xz 文件名 (生成文件名.xz)解压 unxz 文件名.xz
对源文件进行压缩
tar 打包和解包
目录必须要先打包才能压缩
用法:
打包:tar -cvf 目标包(*.tar) 源包或目录
解包:tar -xvf 源包(*.tar)
选项:
-c (create) 归档(打包)
-v (verbose详细的)显示打包过程
-x (extract提取)解包
-f (file)后面跟文件名字
-z 以gzip方式进行压缩
-j 以bzip2方式压缩
-J 以xz的方式进行压缩
-C (directory)指定拆包路径
注意:c和v的选项位置可以随意,但是f必须放在最后,因为f后面必须跟文件名
打包和压缩结合使用
使用gzip方式压缩/解压目录
打包:tar -zcvf 目标包(*.tar.gz) 源包
拆包:tar -zxvf 源包(*.tar.gz)
使用bzip2方式压缩/解压目录
打包:tar -Jcvf 目标包(*.tar.bz2) 源包
拆包:tar -Jxvf 源包(*.tar.bz2)
使用xz方式压缩/解压目录
打包:tar -jcvf 目标包(*.tar.xz) 源包
拆包:tar -jxvf 源包(*.tar.xz)
其他方式解压:
万能解压方式拆包:tar -xvf 源包
指定拆包路径
tar -xvf 源包 -C 路径
网络
网络相关概念
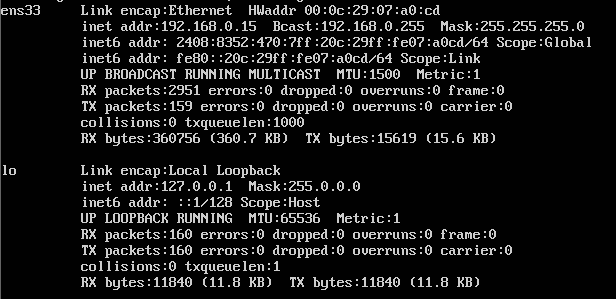
MAC 地址:(图中的HWaddr)物理地址,也叫做硬件地址。用来定义网络设备的相关信息。MAC地址是网卡是只读的,是无法更改的,采用16进制表示,长度是6个字节(48bit)。分为前24位和后24位,前24位由IEEE决定分配,后24位由厂商定制
IP地址: (图中的inet addr)互联网上每一个网络和电脑分配一个逻辑地址,常见的IP地址分为ipv4(图中的inet addr)和ipv6(图中的inet6 addr).
ipv4是4个字节,32bit
ipv6是16个字节,128bit
ipv4地址
1.使用点分用十进制
2.它是识别主机的唯一标识
3.IP地址由 网络号 和 主机号 组成。
ip地址的分类
A类:网络号占一个字节,主机号占三个字节,规定最高位固定是0
B类:网络号占两个字节,主机号占两个字节,规定最高位固定是10
C类:网络号占三个字节,主机号占一个字节,规定最高位固定为110
D类和E类:不常用
网络的划分:
| 网络号 | 主机号 | 最高位 | 范围 | |
| A类 | 1 | 3 | 0 | 0~127 |
| B类 | 2 | 2 | 10 | 128~191 |
| C类 | 3 | 1 | 110 | 192~223 |
| D类 | 组播 | 组播 | 1110 | 224~239 |
| E类 | 预留,未使用 |
广播地址(在图中为Bcast):网段+最大数
例子:78.8.8.8 广播为78.255.255.255 因为78是A类,所以网段为78,其余的全部都是255
子网掩码
(在图中是Mask)子网掩码的作用是从ip中分离出网络号(也间接分离出了主机号)。比如:192.168.1.1(1100 0000 1010 1000 0000 0001 0000 0001),子网掩码是(1111 1111 1111 1111 1111 1111 0000 0000),那么将这两个二进制取与(&),得到的就是(1100 0000 1010 1000 0000 0001 0000 0001 0000 0000),这个就是192.168.1.1的网络号192.168.1.0
子网掩码的两种表达形式:
点分十进制:比如 255.255.255.0
在ip后面加上/:比如 192.168.1.0/26 其中26代表网络号有26位
1.网络号并非严格按照ABC三类实行8、16、24位划分,而是采用了子网划分等技术
由于ipv4的短缺,子网划分技术由此诞生,主要是为了提高ip的利用率,比如一个公司网络号为192.168.1那么它最大可以容纳254台主机(排除了网络地址192.168.1.0和广播地址192.168.1.255),如果这个这家公司最多只有50台主机,那么就会有204个ip被浪费。
2.如何划分网段。
注意,子网掩码是一串连续的1或者0,例如:1111 1111 1111 1111 1111 1111 1100 0000(正确格式) 1111 1111 1111 1111 1111 1111 0011 0000(不连续,错误格式)
假设有一个c类网络号,192.168.1,我希望将其划分为27位网络号,那么就需要占用主机号三位,
子网掩码就是255.255.255.224(1111 1111 1111 1111 1111 1111 1110 0000)。
如何将这其划分为不同的网段呢,那么就需要看主机号的前三位,我们可以清晰的认识到,最后五位不管如何变化都会被0与之后变为0 。而前三位则可以有2^3种情况,即8种,那么最后就可以划分出八个不同的网段,也就是划分出8个网络号:
192.168.1.0/27 (1100 0000 1010 1000 0000 0001 0000 0000)
192.168.1.32/27 (1100 0000 1010 1000 0000 0001 0010 0000)
192.168.1.64/27(1100 0000 1010 1000 0000 0001 0100 0000)
192.168.1.96/27(1100 0000 1010 1000 0000 0001 0110 0000)
192.168.1.128/27 (1100 0000 1010 1000 0000 0001 1000 0000)
192.168.1.160/27 (1100 0000 1010 1000 0000 0001 1010 0000)
192.168.1.192/27 (1100 0000 1010 1000 0000 0001 1100 0000)
192.168.1.224/27(1100 0000 1010 1000 0000 0001 1110 0000)
网关
网关(Gateway)是计算机网络中的一种设备或服务器,用于连接不同网络或协议之间进行数据转发和处理。它在网络层以上实现网络互连,是最复杂的网络互连设备,仅用于两个高层协议不同的网络互连。
网关的主要功能包括:
协议转换:网关可以在使用不同的通信协议、数据格式或语言,甚至体系结构完全不同的两种系统之间,充当一个翻译器。
路由选择:网关可以决定数据包应该通过哪条路径或哪个网络接口发送,以便有效地将数据包从源地址传送到目标地址。
数据处理:网关可以对收到的信息进行重新打包,以适应目的系统的需求。
例如,如果你有两个网络A和B,网络A的IP地址范围为“192.168.1.1~192.168.1.254”,网络B的IP地址范围为“192.168.2.1~192.168.2.254”。在没有路由器的情况下,两个网络之间是不能进行TCP/IP通信的。而要实现这两个网络之间的通信,则必须通过网关。如果网络A中的主机发现数据包的目的主机不在本地网络中,就把数据包转发给它自己的网关,再由网关转发给网络B的网关,网络B的网关再转发给网络B的某个主机。
简单来说,网关就是让主机和其他不在同一网络下主机通信段中间商
DNS
DNS(Domain Name System,域名系统)是因特网上作为域名和IP地址相互映射的一个分布式数据库,能够使用户更方便地访问互联网,而不用去记住能够被机器直接读取的IP数串。通过主机名,最终得到该主机名对应的IP地址的过程叫做域名解析(或主机名解析)。
域名解析协议,实际上是分布在internet上的主机信息数据库,其作用是实现ip地址和域名之间转换
DHCP
DHCP(Dynamic Host Configuration Protocol,动态主机配置协议)是一种网络管理协议,用于集中对用户IP地址进行动态管理和配置。其主要作用是自动分配IP地址、子网掩码、默认网关、DNS服务器等网络配置信息给连接到网络的设备。
网络相关的命令
ifconfig
1.查询
ifconfig 查询所有网卡信息
ifconfig 设备名 只查询指定网卡信息
2.设置网卡
设置ip地址: ifconfig 网卡设备名 ip地址
设置子网掩码:ifconfig 网卡设备名 netmask 子网掩码
设置广播地址:ifconfig 网卡设备名 broadcast 子网掩码
注意只是临时修改。
3.启动和关闭网卡
禁用网卡 : ifconfig 网卡设备名 down
启用网卡 : ifconfig 网卡设备名 up
ping
网络检测 :ping
网络管理
service network-manager stop 停止网络管理
service network-manager start 打开网络管理
service network-manager restart 重启网络管理
软件安装与卸载
debian分支的安装包后缀为.deb
red hat分支安装包后缀为.rpm
在线安装与卸载:
apt-get 在线安装的方式,安装的时候会检查依赖,并一起下载下来
准备工作:
1.ubuntu联网:检查网络
2.设置安装源:/etc/apt/sources.list
3.apt-get update 更新源
安装
命令格式 :sudo apt-get install 软件名
软件例子 sl(小火车) cmatrix(代码雨)bastet(俄罗斯方块)oneko(追逐鼠标的猫)frozen-bubble(泡泡龙)openssh-server(远程链接服务器)
卸载
卸载软件:sudo apt-get remove 软件名
下载不安装
sudo apt-get domnload 软件名字
查看安装的软件
apt list --installed 列出安装的软件,建议使用 apt list --installed | grep 软件名
dpkg-query -l 列出ubuntu中安装的软件 建议使用 dpkg-query -l | grep 软件名
离线安装:
dpkg:不会检查依赖文件
sudo dpkg -i 软件包名
sudo dpkg -l 软件名 显示安装的版本信息
sudo dpkg -P 软件名 完全卸载(包括配置文件)
shell脚本
Shell脚本是一种用于自动执行一系列命令的脚本语言,它运行在Unix/Linux操作系统的Shell环境中。Shell脚本中的内容通常包括一系列命令、控制结构、变量定义和函数等,用于执行特定的任务或自动化一系列操作。其主要目的是执行一系列命令。这些命令可以是系统命令、其他Shell命令、或者自定义的脚本命令。
shell脚本有着较为严格的格式规范,它是一种解释性语言。不需要编译就可以执行。解释器逐行读取源代码,然后逐行解释(或执行)源代码。其脚本文件通常以.sh结尾
使用
1.shell脚本的基本格式
#!/bin/bash
#shell脚本通常以一行特殊的注释作为文件头,目的是告诉系统应当使用哪种编译器执行
mkdir ./
#shell脚本可以使用系统命令、其他Shell命令、或者自定义的脚本命令。2.修改文件权限
/*假设我有一个脚本文件 1.sh,那么它有以下三种执行方式*/
/*这种方式会在一个新的子Shell中执行脚本。这意味着脚本中定义的所有变量和环境更改都只存在于该子Shell中,脚本执行完成后,这些变量和环境更改不会影响到父Shell。此外,使用这种方式执行脚本,脚本文件必须具有执行权限*/
./1.sh
/*这种执行方式和上一种相同,但是不需要文件具有执行权限*/
bash 1.sh
/*这种方式会在当前Shell中执行脚本,而不是在新的子Shell中。这意味着脚本中定义的所有变量和环境更改都会影响到当前Shell。换句话说,脚本执行完成后,你可以在当前Shell中访问脚本中定义的所有变量。*/
source 1.shshell中的变量
用户自定义变量
1、定义变量:Shell支持以下三种定义变量的方式:
variable是变量名,value是赋给变量的值。但有一点需要注意:变量中默认存放的值都是字符串,并且变量名、等于号和值之间不可添加空格
//第一种
variable=value
/*如果value不包含任何空白符(例如空格、Tab缩进等),那么可以不使用引号。*/
//例如:
name=John
/*这行命令定义了一个变量name,并将其值设置为John。*///第二种
variable='value'
/*单引号' '中的任何字符都会原样输出,单引号字符串中的变量是无效的。*/
//例如:
greeting='Hello, $name'
/*这行命令定义了一个变量greeting,并将其值设置为Hello, $name。注意,这里的$name不会被替换为name变量的值,因为它被单引号包围了。*///第三种
variable="value"
/*双引号" "中可以有变量,双引号里可以出现转义字符。*/
//例如:
greeting="Hello, $name"
/*这行命令定义了一个变量greeting,并将其值设置为Hello, $name。这里的$name会被替换为name变量的值,因为它被双引号包围了。*/2、变量命名规则:变量名可以包含字母(大小写敏感)、数字和下划线_,不能包含其他特殊字符。变量名不能以数字开头,但可以包含数字。不要使用Shell的关键字(例如if、then、else、fi、for、while等)作为变量名,以免引起混淆1234。
3、使用大写字母表示常量:习惯上,常量的变量名通常使用大写字母,例如PI=3.14
变量的引用
在shell脚本语言中,主要有两种变量引用方法——$变量名和${变量名}
//第一种——$变量名
/*这种方式是最常见的,它会将变量名替换为变量的值。*/
//例如
name="John"
/*那么echo $name会输出John。*///第二种——${变量名}
/*在Shell脚本中,${变量名}这种方式用于引用变量的值。花括号{}可以帮助Shell解释器识别变量名的边界。*/
//例如
name = "欧尼"
echo "Hi,$name酱"
/*Shell解释器会将$name酱作为整体来看,试图找到一个叫做name酱的变量,而不是name。因为它无法找到name酱这个变量而最终输出:Hi,*/
/*这时就需要一个{}*/
echo "Hi, ${name}酱"
/*这时就会得到预期结果:Hi,欧尼酱*/echo
在shell脚本中echo命令用于在终端上显示一行文本或变量的值,注意,echo会自带换行功能
//1、显示普通字符串,例如:
echo "Hello,World"
//将会在终端上打印:
Hello,World//2、显示变量的值,例如:
name = "john"
echo $name
//将会在终端显示:
john//3、显示转义字符,例如:
echo -e "Hello,\nworld"
//会在终端显示:
Hello,
world//4、显示命令的执行结果,例如:
echo "$(cat 1.txt)"
//将会在终端中显示cat 1.txt的结果补充:在shell脚本中,常常使用反引号`和$()来执行一个命令,并将结果赋值给一个变量,例如:
result=`cat 1.txt`或者result=$(cat 1.txt)
//5、将输出重定向到文件,例如:
echo "Hello,world" > hello.txt
//会将Hello,world写入到文件hello.txt中,如果文件不存在,会创建一个补充:
在shell脚本中可以使用-n来阻止echo自动换行,例如:
echo -n "Hello, "
echo "World"
//输出:
Hello,World也可以使用-e来让echo可以执行转义符号,例如:
echo -e "Hello,\nworld" 会在终端显示:
Hello,
world还可以使用printf,例如printf “age = %d” $num
输入
在shell脚本中,有两种主要的输入方式——参数传递和read命令
read命令
read命令是一种交互式方法,它支持脚本向用户提问并等待。read命令会将脚本用户输入的数据赋给一个或多个变量。
基本用法:read 变量1 变量2 ...
read age
/*这个用法会读取用户的输入,并赋值给age*/
read a b c
echo "a = $a,b = $b, c = $c"
/*在这个用法中,数据的输入必须要对应*/
//例如输入 1 2 3:
a = 1,b = 2, c = 3
/*如果输入的数和变量个数不对,则会截断或者补充在末尾*/
//例如输入 1 2:
a = 1,b = 2, c =
//例如输入 1 2 3 4:
a = 1,b = 2, c = 3 4-p选项用法
-p会允许在命令行中增加一个提示信息
//例如:
read -p "请输入你的名字:" name
//显示:
请输入你的名字:
//此时会等待用户输入。-t选项用法
-t允许指定命令等待输入秒数,当计时满时,read命令会返回一个非零退出状态
//例如:
read -t 5 var
echo "var = $var"
/*如果5秒没有输入,便会结束输入状态,执行下面的指令*/
var =
/*如果在5秒内输入一个值如1(必须按回车),则出现以下结果*/
var = 1-n选项用法
-n选项允许设置read命令计数输入的字符。当输入的字符数目达到预定数目时,自动退出,并将输入的数据赋值给变量。
//例如:
read -n5 var
echo "var = $var"
/*如果var接受的字符超过一个就会自动退出*/
//例如输入12345:
var = 12345 (这里不换行,原因在后面补充中会讲到)
//如果输入123456:
var = 12345-s选项用法
-s选项能让输入的数据不会显示在终端上,在如同在linux用户登录时,密码不会回显
//例如:
read -s -p "请输入你的密码:" passwd
/*在这个例子中,输入不会回显在界面上*/-a选项用法
-a允许用户输入的数据赋值给一个数组
//例如:
read -a array补充:
read命令在输入之后会自动换行,其实并不是命令自动补充的,而是用户在输入之后会按下回车,比如输入123的时候,用户的整个操作过程是 123回车 ,read会读取这个回车,将其作为结束标识的同时,也会输出这个回车换行信号,下面有一个例子:
#!/bin/bash
read -n5 -p "number: " num
echo "result: $num"
#在输入5个数时的结果
number: 12345result: 12345
#因为我们限定了read只能读取5个数,那么读取到5的时候会自动截断,结果无法换行,让第一条语句和第二条语句显示在了一行
#如果输入1234回车的结果
number:1234(回车)
result:1234
#这里可以清晰地看到换行,因为read读取到了回车信号,这也侧面证明了read命令不会自动换行,而是接受了用户的回车信号参数传递
位置参数:
位置参数通常使用$n的格式,n是从0开始索引,$0是文件名,$1代表的是参数1,$2 代表的是参数2
例子:
#!/bin/bash
echo "脚本名:$0"
echo "第一个参数:$1"
echo "第二个参数:$2"
如果我们将上述脚本保存为 test.sh,并在命令行中这样调用它:./test.sh arg1 arg2,那么脚本的输出将会是:
脚本名:./test.sh
第一个参数:arg1
第二个参数:arg2
特殊变量:
在shell脚本中定义了一些特殊的变量让我们获取参数的额外信息
$*和$@:
这两个特殊变量的作用都是用来引用所有的位置参数的。
例子:
#!/bin/bash
echo "所有参数(\$*):$*"
echo "所有参数(\$@):$@"如果你将上述脚本保存为 test.sh,并在命令行中这样调用它:./test.sh arg1 arg2 arg3,那么脚本的输出将会是:
所有参数($*):arg1 arg2 arg3
所有参数($@):arg1 arg2 arg3但是这两个特殊变量并不完全一样 :
- 相同点:都是引用所有参数。
- 不同点:只有在双引号中体现出来。假设在脚本运行时写了三个参数 1、2、3,则 ” * ” 等价于 “1 2 3″(传递了一个参数),而 “@” 等价于 “1” “2” “3”(传递了三个参数)。
举一个例子来说明:
#!/bin/bash
echo "使用\$*:"
for i in "$*"; do
echo $i
done
echo "使用\$@:"
for i in "$@"; do
echo $i
done如果你将上述脚本保存为 test.sh,并在命令行中这样调用它:./test.sh arg1 arg2 arg3,那么脚本的输出将会是:
使用$*:
arg1 arg2 arg3
使用$@:
arg1
arg2
arg3$$ 当前进程号
这个命令的意思是指当前脚本的进程ID
例子:
#!/bin/bash
echo -e "\$$ = $$"假设这个脚本名为test.sh,那么$$将会获取test.sh执行后的进程ID
$# 位置参数的个数(不包括命令)
这个命令可以读取传递给脚本的参数的个数。
#!/bin/bash
echo "参数个数:$#"如果你将上述脚本保存为 test.sh,并在命令行中这样调用它:./test.sh arg1 arg2 arg3,那么脚本的输出将会是:
参数个数:3$?
上一个命令是否成功执行,如果成功,该结果是0,失败结果是1(这个和C语言的判断相反)
例子:
#!/bin/bash
cat day3
echo -e "\$? = $?"假设这一个目录day3并不存在,那么$?就会返回1,即失败
$? = 1$!
在Shell脚本中,$! 是一个特殊变量,它包含了最后一个后台命令的进程ID(PID)。
#!/bin/bash
sleep 30 &
echo "最后一个后台命令的进程ID:$!"这个脚本将会启动一个后台进程(sleep 30),然后输出这个后台进程的进程ID。
getopts:
在Shell脚本中,getopts 是一个内置的命令行参数解析工具,它的主要目的是从Shell脚本的命令行中解析参数。getopts 被用来分析位置参数,option 包含需要被识别的选项字符。如果这里的字符后面跟着一个冒号,表明该字符选项需要一个参数,其参数需要以空格分隔。
getopts 的基本语法是 getopts optstring name [arg]:
optstring:表示要识别的命令行选项形式,如果一个字母后面有一个”:”,表示该命令行选项后面要跟一个参数。例如,如果 optstring 写成 “b:o:h”,表示支持 -b、-o、-h 选项识别,-b 和 -o 选项后面需要跟一个参数。
name:每次调用 getopts,它会将下一个选项放置在 shell 变量 name 中。如果传入命令行中不存在 name 选项,则将其重新初始化。
arg:表示要解析参数,在 shell 脚本中使用时,默认解析的是执行 shell 脚本传入的参数,所以这个部分可省略不写。
当 getopts 识别出各个选项之后,就可以配合 case 进行操作。在操作中,有两个”常量”,一个是 OPTARG,用来获取当前选项的值;另外一个就是 OPTIND,表示当前选项在参数列表中的位移。
以下是一个使用 getopts 的示例:
#!/bin/bash
while getopts ":b:o:h" opt_name
do
case $opt_name in
b)
echo "-b Option is recognized, argument=$OPTARG"
;;
o)
echo "-o Option is recognized, argument=$OPTARG"
;;
h)
echo "-h Option is recognized"
;;
?)
echo "Unknown option $OPTARG"
;;
esac
done在这个示例中,getopts 用于解析 -b、-o 和 -h 选项。-b 和 -o 选项后面需要跟一个参数,这些参数可以通过 OPTARG 变量获取。如果 getopts 识别到一个未知的选项,那么它会将这个选项的值放入 OPTARG 变量中,并且 opt_name 的值将会是 ?。
系统环境变量
在操作系统中,具备一些默认含义变量。
PATH 这个环境变量包含了一系列的目录,当你在命令行中输入一个命令时,系统会在这些目录中查找这个命令。如果在当前目录下找不到这个命令,系统就会去 PATH 变量中列出的目录中寻找。
USER 这个环境变量包含了当前登录用户的用户名。
UID 这个环境变量包含了当前登录用户的用户ID。在Unix和类Unix系统中,每个用户都有一个唯一的用户ID。
HOME 这个环境变量包含了当前用户的主目录的路径。在Unix和类Unix系统中,每个用户都有一个主目录,通常是 /home/username。
PWD 这个环境变量包含了当前工作目录的绝对路径。当你在命令行中移动到不同的目录时,PWD 变量的值会改变。
通过$使用这些系统环境变量,例如:
#!/bin/bash
echo -e "$PATH = $PATH"
echo -e "$PWD = $PWD"shell脚本中的控制语句
说明性语句
以#开头到改行结束,不被解析(注释)
功能性语句
任意的shell命令
test测试语句
test语句可以测试对象:字符串,整数,文件。
在Shell脚本中,test 命令用于检查某个条件是否成立,它可以进行整数(test不能直接处理浮点数,需要借助其他工具)、字符和文件三个方面的测试。test 命令有两种基本的写法:
test 表达式:这种写法直接使用 test 命令,后面跟着你想要测试的表达式。例如,test $num1 -eq $num2 会检查 $num1 是否等于 $num2。
[ 表达式 ]:这种写法是 test 命令的简写形式。它使用方括号 [] 来代替 test 命令,但是表达式的内容和 test 命令是一样的。例如,[ $num1 -eq $num2 ] 和 test $num1 -eq $num2 是等价的。
请注意,无论你使用哪种写法,表达式两边都需要有空格。例如,[ $num1 -eq $num2 ] 是正确的,但是 [$num1 -eq $num2] 是错误的。
测试的返回结果有0和非0,其中0表示测试结果为真,非0表示测试结果为否(与C语言的表示相反)
数值(整数)测试
以下是常见的数值比较选项
-eq:等于-ne:不等于-gt:大于-ge:大于等于-lt:小于-le:小于等于
例子:
#格式1
#!/bin/bash
num1=10
num2=10
if test $num1 -eq $num2
then
echo "num1 等于 num2"
else
echo "num1 不等于 num2"
fi#格式2
#!/bin/bash
num1=10
num2=10
if [ $num1 -eq $num2 ]
then
echo "num1 等于 num2"
else
echo "num1 不等于 num2"
fi输出
num1 等于 num2字符串测试
以下是常见的字符串比较选项
=或==:等于!=:不等于-z:(zero)字符串长度为零-n:(non-zero)字符串长度不为零
例子:
#格式1
#!/bin/bash
str1="Hello"
str2="Hello"
if test "$str1" = "$str2"
then
echo "str1 等于 str2"
else
echo "str1 不等于 str2"
fi
#格式2
#!/bin/bash
str1="Hello"
str2="Hello"
if [ "$str1" = "$str2" ]
then
echo "str1 等于 str2"
else
echo "str1 不等于 str2"
fi
文件测试
以下是一些常见的文件测试选项
-e:文件存在-r:文件可读-w:文件可写-x:文件可执行-f:文件是普通文件-d:文件是目录-s:文件大小非零
例子:
#格式1
#!/bin/bash
filename="test.txt"
if test -d "$filename"
then
echo "$filename 是一个目录"
else
echo "$filename 不是一个目录"
fi
#格式2
#!/bin/bash
filename="test.txt"
if [ -d "$filename" ]
then
echo "$filename 是一个目录"
else
echo "$filename 不是一个目录"
fi注意:整数测试的时候可以不需要在表达式中添加"",但是字符串测试和文件测试需要在表达式中添加""
多个条件并行
与
-a:这个操作符表示逻辑与(AND)。如果你有两个条件,你希望当这两个条件都为真时,整个表达式才为真,那么你可以使用 -a 操作符来连接这两个条件。例如:
if [ $num -gt 10 -a $num -lt 20 ]
then
echo "num 在 10 和 20 之间"
fi也可以使用&&符号
num1=150
num2=200
if [ $num1 -gt 100 ] && [ $num2 -gt 100 ]
then
echo '两个数都大于100'
else
echo '不是所有的数都大于100'
fi或
-o:这个操作符表示逻辑或(OR)。如果你有两个条件,你希望只要有一个条件为真,整个表达式就为真,那么你可以使用 -o 操作符来连接这两个条件。例如:
if [ $num -lt 10 -o $num -gt 20 ]
then
echo "num 不在 10 和 20 之间"
fi也可以使用||符号
num1=100
num2=50
if [ $num1 -gt 100 ] || [ $num2 -gt 100 ]
then
echo '至少有一个数大于100'
else
echo '没有数大于100'
fi非
!:这个操作符表示逻辑非(NOT)。如果你有一个条件,你希望当这个条件为假时,整个表达式才为真,那么你可以在这个条件前面加上 ! 操作符。例如:
if [ ! -e "$filename" ]
then
echo "文件 $filename 不存在"
fi(结构语句)控制语句
作用:根据程序的运行状态、输入的数据、变量的取值、控制信号以及运行的时间等来控制程序运行的流程。
1、if 判断
格式1:
if 测试语句
then
执行语句
fi格式2:
if 测试语句
then
语句1
else
语句2
fi2、多路分支case //进行字符串比较
case 字符串变量 in
模式1)
语句
;;
模式2)
语句
;;
*)
语句
;;
esac举例:
#!/bin/bash
echo "Do you know Java Programming?"
read -p "Yes/No? :" Answer
case $Answer in
Yes | yes | y | Y)
echo "That's amazing."
;;
No | no | N | n)
echo "It's easy. Let's start learning from yiibai.com."
;;
esac3.for循环
格式1:
for 变量 in 值列表(值和值之间使用空格)
do
语句
done格式2:
for(( i=0;i<10;i++ ))
{
语句
}举例:
循环数字
for i in {1..10}
do
echo $i
done循环字符串
for i in "Hello" "World"
do
echo $i
done
遍历目录
for file in /path/to/directory/*
do
echo $file
done
补充:for中的列表如何使用一个范围
例如我先打印1-99的所有值:
#!/bin/bash
for i in {0..99}
do
echo $i
done 4、while循环
在这个结构中,条件通常是一个测试表达式,如果这个表达式的结果为真(返回值为0),那么do和done之间的命令就会被执行。当表达式的结果为假(返回值非0)时,循环就会结束。
while 测试条件
do
语句
done举例:
#!/bin/bash
num=1
while [ $num -le 10 ]
do
echo $num
num=$(( $num + 1 ))
done
数学扩展
数学扩展能让变量进行数学运算,但是注意,只能是整数进行运算,如果使用浮点数会被当做字符串处理
1、( (表达式))
用法1: ((表达式))
用法2:((表达式1,表达式2…))
注意:
$((表达式)):这种形式用于算术扩展。它会计算表达式的值,并将结果替换到原处。例如,在echo $((123 + 1))中,$((123 + 1))会被替换为124,所以如果想将(())结果复制给新变量或者使用都需要使用$((表达式)):这种形式通常用于条件判断和算术运算。例如,在if ((expression))或while ((expression))中,如果表达式的结果为非零值,则条件为真。此外,((表达式))也可以用于简单的算术运算,例如((a = 123 + 1))3
总的来说,((表达式))和$((表达式))的主要区别在于,前者通常用于条件判断和算术运算,而后者用于算术扩展
举例
#!/bin/bash
a=5
b=7
echo $((a*b)) # 输出352、$[]
$[]是用于进行数学运算的一种方式。它支持加(+)、减(-)、乘(*)、除(/)和取模(%)等基本的数学运算
RET = $[表达式]
注意事项:
$[]的结果可以被赋值给变量,也可以直接用于输出或其他命令
举例:
a=5
b=7
echo $[a+b] # 输出123、let
let命令是用于执行基本的算术运算和逻辑运算的内置命令。它可以直接在命令行上计算表达式的值,并将结果输出到标准输出
用法:let RET=$NUM1+$NUM2
注意:
- 运算符之间不能有空格
- 必须有一个变量去接受表达式运算的结果
- 参与运算的只能是整数
举例:
#普通运算操作
let a=5+4
echo $a # 输出9
#自增自减运算
let no++
let no--
#简写
let no+=10
let no-=204、expr
expr命令是一个功能强大的命令,用于在UNIX/LINUX下求表达式变量的值,一般用于整数值,也可用于字符串
基本语法:expr expression
举例:
#简单的数学运算
expr 5 + 7 # 输出12
#计算字符串长度
expr length "this is a test" # 输出14
#抓取字符
expr substr "this is a test" 3 5 # 输出"is is"
注意:
- expr 自带输出功能
- 运算符的前后一定要有空格,不然会被当做字符串
- 使用变量的时候必需要有$
- 让计算结果保存在变量中:
NUM3=`expr 1 + 2`或者NUM3=$(expr 1 + 2) - 在使用乘法的时候,必须使用转义字符\
- 在使用()改变优先级时,必须要使用转义符号\,否则会被判定为数组。
- <>也需要使用转义符号,否则会成为重定向符号
系统管理命令
adduser
选项 -home :指定用户主目录 -uid:指定用户的编号 -gid:指定用户组编号
su
作用:切换用户
新添加的用户不在sudoers文件中,在其中添加 用户名 ALL=(ALL:ALL)ALL
passwd
作用:修改密码
格式:
passwd 用户名
usermod
作用:用户信息的修改
sudo usermod 修改后的内容 需要修改的内容
选项
-c 修改passwd文件中第五个区域的内容,即登录名:
sudo usermod -c 修改后的登录名 原来的用户名
-d 修改用户的主目录
sudo usermod -m -d 修改后的目录 修改前
-g 修改用户的所属组
sudo usermod -g 组名 用户名
-aG
作用:小组成员的附加,将用户添加到对应的小组中
sudo usermod -aG 组名 用户名
sudo gpasswd -d 用户名 组名
将对应的用户移出小组
deluser
作用:删除用户和组
deluser 用户名 删除用户
delgroup 组名 删除组名
磁盘管理
查看磁盘使用的情况:df
df 是一个在 Unix 和类 Unix 系统(包括 Linux)中常用的命令,用于显示文件系统的磁盘空间使用情况。df 是 “disk filesystem” 的缩写。
基本的 df 命令会列出所有已挂载的文件系统的信息,包括设备名、总的磁盘空间、已使用的磁盘空间、剩余的磁盘空间、已使用的磁盘空间的百分比,以及文件系统挂载的位置。
选项: -h
-h 选项会使 df 以人类可读的格式显示磁盘空间信息,如 K(千字节)、M(兆字节)、G(吉字节)等。
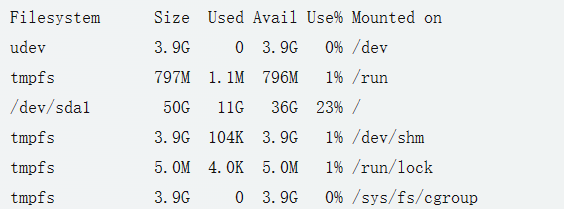
/dev/sda1 是主文件系统,它有 50G 的总空间,已使用 11G,剩余 36G,使用率为 23%。
挂载命令:mount
挂载,在Linux和其他Unix-like系统中,mount命令用于挂载文件系统,linux中的根目录以外的文件想要被访问,需要将其关联到根目录下的一个目录来实现,这种关联我们叫做挂载。将特定的存储设备(如硬盘,光盘,USB驱动器等)或者特定的文件系统(如ISO文件,磁盘镜像等)连接到操作系统的文件系统的一个特定点上,这个特定点被称为挂载点。
挂在命令格式如下:
mount -t type device dir在这里,type是文件系统的类型,device是要挂载的设备,dir是挂载点。
在这个命令中:
-t type:这是一个选项,用于指定文件系统的类型。type是你要挂载的文件系统的类型,例如ext4、ntfs、iso9660等。device:这是你要挂载的设备的设备文件路径。例如,硬盘通常是/dev/sda1、/dev/sdb1等,光盘通常是/dev/cdrom,USB 驱动器可能是/dev/sdc1等。dir:这是你要将设备挂载到的目标目录,也就是挂载点。这个目录必须已经存在,mount命令不会为你创建它。
例如,如果你有一个ext4文件系统的设备在/dev/sdb1,你想把它挂载到/mnt/mydisk,你可以使用以下命令:
mount -t ext4 /dev/sdb1 /mnt/mydisk如果你没有指定文件系统类型,mount会自动尝试识别它。所以,你也可以使用这种格式mount 设备名 目标子目录:
mount /dev/sdb1 /mnt/mydisk取消挂在: umouont
格式: umount 目标设备名 或者 umount 目标子目录
在这里,目标子目录 是你之前挂载设备的目录,设备名 是你要卸载的设备的设备文件路径。
例如,如果你之前使用 mount /dev/sdb1 /mnt/mydisk 命令挂载了一个设备,你可以使用以下命令来卸载它:
umount /mnt/mydisk或者
umount /dev/sdb1请注意,只有当文件系统没有被使用(也就是说,没有任何进程正在访问挂载点目录)的时候,你才能卸载它。如果文件系统正在被使用,umount 命令会失败,并显示一个错误消息。
fdisk:磁盘管理
可以使用 fdisk -l列出所有分区表
m:显示菜单和帮助信息。a:设置活动分区标记/引导分区。d:删除分区。n:新建分区。p:显示分区信息。q:退出不保存。w:保存修改并退出。
常见的文件系统
Windows:
FAT32、NTFS、exFAT
Linux:
ext、ext2、ext3、ext4、xfs、linuxswap、VFAT
macos
HFS/HFS+
进程管理
查看进程信息
静态显示——ps
ps 是一个在 Unix 和类 Unix 系统(包括 Linux)中常用的命令,用于显示当前系统中运行的进程的状态。ps 是 “process status” 的缩写。
基本用法:
- ps:显示当前用户的所有正在运行的进程列表。
- ps -ef:显示系统中所有进程的列表,包括其他用户的进程。
- ps -aux:显示详细的进程信息,包括 CPU 和内存使用情况等
每个进程的信息包括进程 ID(PID)、父进程 ID(PPID)、终端、CPU 使用率、内存占用等。
例如,如果你想查看当前系统运行状态中指定的进程信息,你可以使用 ps -ef | grep 进程关键字 命令。如果你想查看指定用户的进程信息,你可以使用 ps -u 用户名 命令。
ps -ef

- UID:程序被该 UID 所拥有,指的是用户 ID。
- PID:就是这个程序的 ID。
- PPID:则是其上级父程序的 ID。
- C:CPU 使用的资源百分比。
- STIME:系统启动时间。
- TTY:登入者的终端机位置。
- TIME:使用掉的 CPU 时间。
- CMD:所下达的指令。
ps -aux

- USER:进程的所有者,即运行该进程的用户的用户名。
- PID:进程 ID,是进程的唯一标识符。
- %CPU:进程使用的 CPU 资源的百分比。
- %MEM:进程使用的物理内存的百分比。
- VSZ:进程使用的虚拟内存总量,单位是 KB。
- RSS:进程使用的、未被换出的物理内存大小,单位是 KB。
- TTY:与进程关联的终端的名称。
- STAT:进程的状态。
- START:进程的启动时间。
- TIME:进程使用的总 CPU 时间。
- COMMAND:启动进程的命令。
在这两个命令中,-e 和 -a 选项都是用来选择要显示的进程的。-e 选项会选择所有进程,而 -a 选项会选择除了无终端的系统进程和会话领导进程之外的所有进程。
-f 和 -u 选项都是用来选择显示格式的。-f 选项会显示完整格式,而 -u 选项会显示以用户为中心的格式。
-x 选项是用来包含无终端的进程的。如果没有 -x 选项,ps 命令只会显示有控制终端的进程。
动态显示——top
top 是一个在 Linux 和其他类 Unix 系统上常用的实时系统监控工具。它提供了一个动态的、交互式的实时视图,显示系统的整体性能信息以及正在运行的进程的相关信息。
以下是 top 命令的一些基本用法:
top:直接运行 top 命令会显示一个动态更新的视图,包括系统的运行时间、平均负载、运行的进程和线程数目、CPU 使用率、内存使用情况等。
- top -d number:-d 选项用于指定 top 命令的刷新时间间隔,单位为秒。
- top -n number:-n 选项用于指定 top 命令运行的次数后自动退出。
- top -p pid:-p 选项用于仅显示指定进程 ID 的信息。
在 top 运行时,你还可以使用一些按键命令进行操作,例如:
- k:终止一个进程。
- r:重新设置一个进程的优先级。
- h:显示帮助信息。
kill:向指定进程发送信号
kill 是一个在 Unix 和类 Unix 系统(包括 Linux)中常用的命令,用于发送信号给进程,通常用于终止进程
基本的 kill 命令的使用格式如下:
kill [signal] pid- signal 是你想要发送的信号的编号。如果不指定信号,kill 命令会发送 SIGTERM(信号 15)来尝试正常终止进程。如果进程不能被 SIGTERM 终止,你可以发送 SIGKILL(信号 9)来强制终止进程。
- pid 是你想要终止的进程的进程 ID。你可以使用 ps、pidof、pstree、top 等命令来查找进程的 ID。
举例:
例如,如果你想要终止进程 ID 为 1234 的进程,你可以使用以下命令:
kill 1234或者,如果你想要强制终止进程,你可以使用以下命令:
kill -9 1234如果你想查看系统支持的所有信号,你可以使用 kill -l 命令。这个命令会列出所有可用的信号,包括它们的编号和名称。
常用的信号
- SIGINT(信号 2):中断信号,通常由 Ctrl+C 键发送。
- SIGQUIT(信号 3):退出信号,通常由 Ctrl+\ 键发送。
- SIGKILL(信号 9):强制终止信号,可以无条件终止进程。
- SIGSTOP(信号 19):暂停信号,通常由 Ctrl+Z 键发送。
- SIGCONT(信号 18):继续信号,与 SIGSTOP 相反。
补充
man
手册命令,第一章shell命令,第二章系统函数,第三者库函数等,注意,man命令会返回第一个匹配的信息,如果你想查的信息在第三章,如果第一章恰好有一个相同的标志,那么会错误地返回第一章的信息
通配符:
? :匹配一个任意的字符
* :匹配多个字符
history: history 行数 查看命令历史
关于管道符号|和xargs(execute arguments)的一点猜想:
ls | grep “字符” 这个命令可以在当前目录中筛选出来符合要求的文件名字,但是如果希望将这些文件删除,却并不能仅仅使用ls | grep “字符” | rm ,目前所了解的信息是,ls的结果是标准输出,利用管道以标准输入的方式作为rm的参数是不可行的,rm拒绝读取标准输入的数据作为参数,而xargs对作用则是将标准输入变成命令参数。
不过我疑惑的点是:为何Linux的设计者会让有些命令拒绝读取标准输入的数据作为命令参数。
我的想法是这样的,即便是能使用标准输入的grep命令也仅仅只处理ls返回的字符信息,假设我的目录中有1.c 一个文件,那么我使用 ls | grep "c"命令,对于grep来说,它收到了一个文本信息,这个信息中的数据是1.c 一个字符串,所以grep打印出了1.c 这个结果, 但如果我知道这个目录中有且仅有这一个文件,并且我的目的是希望在1.c这个文件内容中找出包含字母c的信息呢,那么这里就出现了二义性。
那么消除这个二义性的方法之一就是干脆不要让标准输入的数据成为命令参数,就让其安静的单纯的作为一个文本信息便可。如果返回的字符串是一个文件名,并且希望访问这个文件中的内容,那么请使用xargs告诉bash,我想访问这个文件内容,请将这个字符串看作文件名,那么命令应该这样写 ls | xargs grep "c",在这个时候,grep会将ls的标准输出结果1.c看作文件的名字,然后去文件中寻找含有c的信息。
以下验证我的猜想的证明:

这里可以知道我的new5目录中只有一个1.c文件

这里看到了1.c中的内容

不使用xargs的情况下输出的是文件名称

使用xargs的情况下输出的是文件内容
