KMP算法是为了解决字符串在查找过程中不断进行重复寻找而导致低效率的问题。
假设一个字符串(主串):
ABABAABBABAABBABABABAAABABAA下面是我们的目标字符串,(也可以叫做子串、模式串)
ABABAAABABAA在最简单的算法中便是对主串进行依次排查:

当发现不同之后,便会向右移动,然后继续对照。

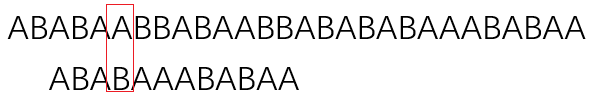
经过不断的移动之后,终于在末尾确认了字符串。

虽然最终能得到结果,但是效率却非常低下,在移动的过程,能够很清晰地观察到:“第一张图片已经确认了第二个字母是B,我们很清楚地知道A不可能和B相同,那么就没有必要进行第二张图片的比较”。
在主串中,对字符进行比较的指针每找到一个不同的字母,就必须回到上次开始的下一个位置,所以,由于大量这种重复且无意义地比较导致代码的时间复杂度变得很高,在这种情况下,KMP算法应运而生。
KMP算法地核心就是记住了跳过这种繁琐且不必要的比较,让指向主串指针不回溯,那么就会大大节约时间,比如:

第一步之后,就可以直接跳到这一步,因为中间已经验证过了,这里有点难以想明白,但是如果把主串当做黑盒,你不知道里面的任何东西,只有在比较之后,里面的字符才会显示出来,那样就好理解多了。
接下来重点来了,我们要怎么知道能够跳多远呢。
这就要引入几个重要的概念:
最长相同子序列:
我们在比较之后,相当于将主串的信息记录在了子串上,在子串第一个和主串字母不同的位置之前,都是和主串一模一样。
所以我们可以将目光落在子串上:
ABABA
我们先看这一个序列,然后将这个序列拆分为前缀和后缀。这个子串可以拆分的所有情况是:A-A ,ABA-ABA
为什么要拆分呢?
因为我们需要记录子串的信息,之后移动子串的时候可以排除掉重复的情况
接着我们开始从前后缀分析,注意,前缀必须以最前面的字符开头并且最长不能等于子串长度,后缀必须以最后面的字符结尾,同样最长也不能等于子串长度。
前缀-ABAB 后缀-BABA由于不相同,所有不是我们的需求,再看第二个:前缀-ABA 后缀ABA,相同了,这是我们能确保移动且不会错过的步长。
但是每一次移动都要算一次子串显然也方便不到哪里去,所以引入了另外一个概念:
next[]数组
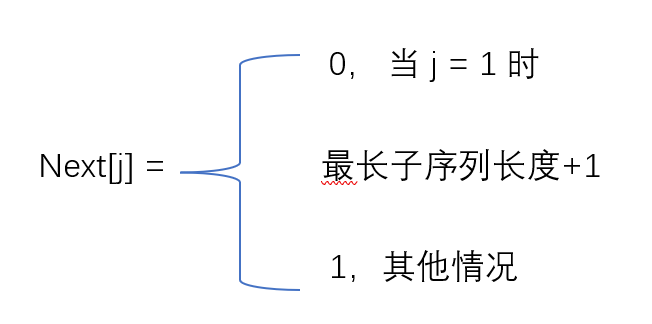
在任务开始之前,我们会提前对子串进行分析,并将分析之后的数据放在数组里面。
拿之前的ABABAAABABAA分析。
那么对应的next数组的值就是{0,1,1,2,3,4,2,2,3,4,5,6}
那么为什么要加1呢?
因为next数组记录的是解决方案的位置,比如

依旧是这个例子,当我们发现第七位的前面最长子序列是1的时候,那么子串的A就能和被绿色方框左边的A对齐,然后,和方框内比较就是第二位的B,所以需要加一。

