数组是什么?
从本质上来讲,数组是一个相同类型的数据集合,如 int a[10] 本质上是10个 int 类型的数紧密地罗列在一起,并且在地址上构成连续。比如地址从0x00~0x40(因为 int 占四个字节)。
接下来要提到的是数组名,数组名其实是一个地址(确切的说,数组名是一个指针常量,这个指针存放着数组的首元素地址,只是习惯上会说数组名是一个地址),而这个地址是这个数组首元素的地址。要注意的一点是,数组的地址和数组首元素的地址是有区别的,我们用下面的例子来分析一下:
#include <stdio.h>
int main(){
//我使用二维数组是方便举例论证,读者在这里也许会有些迷惑,不过不要紧,后面会解释清楚
//此处你可以简单的看成一个int a[2]的一位数组,其他的请暂时忽略
//如果实在看不懂,请直接跳过代码看结论,在本章阅读完成后你就能看懂了
int a[2][2] = {1,2,3,4};
//此处可以简单看成 int *p = &a;
int (*p)[2] = &a;
//这一段,你可看作a[0]的地址和a[1]的地址
printf("首元素a[0]的地址:%p\n",&a[0][0]);
printf("第二个元素a[1]的地址:%p\n",&a[0][1]);
//这一段可以简单的看作整个数组a的地址和下一个内存中地址
printf("数组a的地址:%p\n",p[0]);
printf("在内存中紧挨着数组a的下一个地址:%p\n",p[1]);
}运行结果:
首元素a[0]的地址: 0x7fffcdb9b200
第二个元素a[1]的地址:0x7fffcdb9b204
数组a的地址: 0x7fffcdb9b200
在内存中紧挨着数组a的下一个地址:0x7fffcdb9b208
结论:
我们在代码逻辑中假设了一个 int a[2] 的数组,从结果上我们可以看到,数组的首元素地址和数组的地址都是0x7fffcdb9b200,但是一个指针从首元素地址移动到下一个内存地址(0x7fffcdb9b204)步长是4,而一个指向整个数组的指针,移动到下一个内存地址(0x7fffcdb9b208)后,步长却是8,刚好是我们举例的a[2]空间的总大小,横跨了整个数组。
所以我们总结一下,数组名是数组首元素的地址,而数组地址是整个数组的地址,两个地址虽然一样,但是在性质上有本质的区别。
数组与指针
既然我们在上文中提到了数组名是一个指向数组首元素地址的指针常量,那么数组就必然在命运中和指针绑在了一起,接下来就让我们看一看数组和指针的关系。
我们已经知道了数组名和地址有着不可分割的关系,指针又和地址紧密相连,那么我们同样可以想到用指针来访问数组。
#include <stdio.h>
int main(){
int a[2]={1,10};
int *p = a;
printf("*p = %d\n ",*p);
printf("*(p+1) = %d\n",*(p+1));
}运行结果
*p = 1
*(p+1) = 10
在代码中,我们用一个p存放了数组首元素的指针,那么理所当然,我们解引用*p之后就是a[0]中存储的数据1,那么我们给(p+1)的意思也就是让指针向后移动一位,但我们前文说过,数组中元素的地址是连续的,那么这个指针就移到了a[1]的地址,然后我们将其解引用*(p+1)得到的结果就是a[1]中存储的数据10
我相信看到了这里,读者心中可能有疑问——既然p能+1移动地址,那我用a+1不也可以吗?
其实这也是很多初学者的误区,我们在上文提到过,数组名本质是一个指针常量,这也就决定了数组名是不能进行运算的,你可以改变数组名地址对应的值,但无法改变数组名对应的地址:
#include <stdio.h>
int main(){
int a[2]={1,10};
a++;
}运行结果
1.c: In function ‘main’:
1.c:5:6: error: lvalue required as increment operand
5 | a++;
很明显编译器在这里抛出了一个错误,其实我们仔细思考一下也能想明白,如果数组名存放的地址改变了,是不是也就意味着这个数组在内存中就无法很好的进行定位了,届时可能会造成各种奇怪的问题,当然,我想C语言的开发人员可能会考虑的更多。
指针数组与数组指针
初学者看到这一个标题的时候估计心中可能有疑问——这不是一样的吗?其实不然,这两个词有着本质的区别,让我们去掉这两个词前面的修饰,是不是标题就变成了”数组与指针“了。那我们接下来就仔细探讨一下这对”蛮生兄弟“。
首先我们来说说指针数组,顾名思义就是存放指针的数组。比如 int *p[10] ;我们来分析一下,先想一想 * 和 [] 的优先级,我们通过各种途径都能了解到,[]的优先级是高于 * 的,所以p会和[]先结合,我们再看一看p[]是什么,显然这是一个数组,将int *p[10]连起来看,就是有一个名为p的数组,它有10个元素,每个元素是int*类型。
#include <stdio.h>
int main(){
int a=1,b=10,c=100;
int *p[3]={&a,&b,&c};
for(int i=0;i<3;i++){
printf("p[%d] = %p\n",i,p[i]);
}
}运行结果
p[0] = 0x7ffe0311c7a8
p[1] = 0x7ffe0311c7a4
p[2] = 0x7ffe0311c7a0
从程序代码中,我们就能很清楚的就能看到p的三个元素是什么,这就是指针数组,一个存放指针的数组。
接下来我们聊聊数组指针,有了前面的经验,我们仔细瞧一瞧这个结构 int (*p)[3] ;在这里我们的*被()括了起来,所以*和p先结合,那么*p是什么呢?显然这是一个指针,让我们把其他的加上: int (*p)[3] ;这就是一个指向有三个元素的数组的指针,我们前面学过了数组名是一个数组首元素的地址,假设一个数组int a[3],在数组名前加&就是取整个数组的地址,但是取了之后,我们怎么用指针来接呢?int *?这显然不能,因为现在的地址性质是数组,一个小小的int*肯定接不住,那么 int(*p)[3] 就应运而生。
#include <stdio.h>
int main(){
int a[3]={1,2,3};
int (*p)[3] = &a;
}这就是数组指针的基本用法,但是数组指针特殊的地方是,它存放的是一个数组的地址,我们通常不会单独进行 *(p+1) 的解引用操作,因为我们不知道下一个内存是什么,这种操作是没有意义的,指针数组通常使用在多维数组上,这也是为什么我会在讨论”数组是什么“的时候用二维数组来讨论的原因。
不过有一点值得注意,数组指针和数组的[]里面的数是对应的,一个萝卜一个坑,必须要一一对应,以下行为就是语法错误的典范:
#include <stdio.h>
int main(){
int a[3]={1,2,3};
int (*p)[2] = &a;
}多维数组
我们在上个模块就涉及到了多维数组,那么这个模块我们就拿二维数组作为代表来讲一讲,因为多维数组其实是相通的,你看懂了二维数组,多维数组也就懂了。
一样的,我们来看看例子: int a[2][3] ;我们从形式上应该能大致猜测出a代表的是一个2行3列的数组,当然这是逻辑上的,其实它在内存中的本质还是一维数组,接下来请听我仔细分析:
#include <stdio.h>
int main(){
int a[2][3]={1,2,3,4,5,6};
int (*p)[3] = &a;
printf("&a = %p\n",&a);
printf("a = %p\n",a);
printf("p[0] = %p\n", p[0]);
printf("p[1] = %p\n", p[1]);
for(int i = 0;i<2;i++){
for(int j=0;j<3;j++){
printf("&a[%d][%d] = %p \n",i,j,&a[i][j]);
}
}
printf("\n");
}运行结果
&a = 0x7ffc1838d1a0
a = 0x7ffc1838d1a0
p[0] = 0x7ffc1838d1a0
p[1] = 0x7ffc1838d1ac
&a[0][0] = 0x7ffc1838d1a0
&a[0][1] = 0x7ffc1838d1a4
&a[0][2] = 0x7ffc1838d1a8
&a[1][0] = 0x7ffc1838d1ac
&a[1][1] = 0x7ffc1838d1b0
&a[1][2] = 0x7ffc1838d1b4
我们仔细分析一下这个数组a,
&a[0][0] = 0x7ffc1838d1a0
&a[0][1] = 0x7ffc1838d1a4
&a[0][2] = 0x7ffc1838d1a8
&a[1][0] = 0x7ffc1838d1ac
&a[1][1] = 0x7ffc1838d1b0
&a[1][2] = 0x7ffc1838d1b4
我们可以看到它们的地址全部都是连续的,那就证明二维数组在内存中是按照线性存储的,然后我们又能看到p[0]中存放的是第一行的地址,p[1]存放的是第二行的地址,我们汇总一下就得出以下一个图:
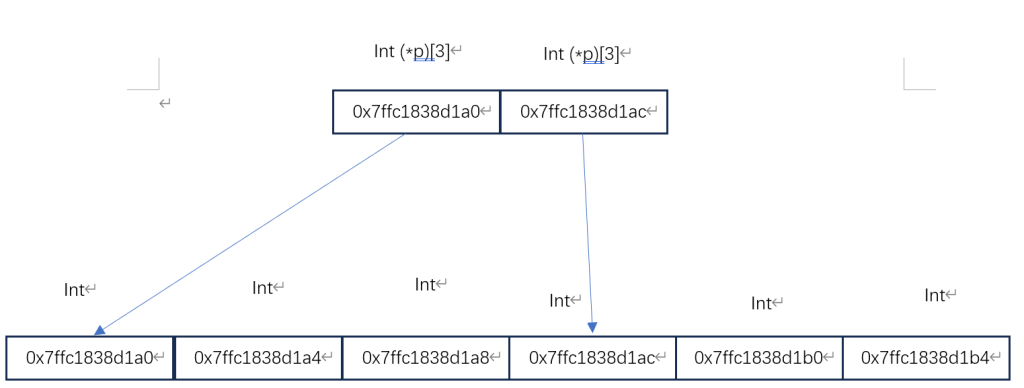
从这里我们很清晰的看到,我们将a[2][3]解析成了两部分,首先是一个一维数组[2],这个数组中存放着两个数组指针int(*)[3],每个数组指针指向了一个包含三个元素的一维度数组int [3];
最终得到的结果就是,a[2][3]中的2,指的是存放了两个指针(也就是数组指针),每个指针指向一个拥有三个元素的数组(也就是一行),注意,这个指针存放的是一个数组的地址,不是数组首元素的地址,这也是为什么图上方的两个方块地址步长为12的原因。
其中我们也得到了一个重要的结论,二维数组的名字是第一行数组的地址,而非第一个元素的地址!
所以,多维数组在内存中呈线性,在逻辑上成空间分布,多维数组都遵循这一个核心,所以你也可以按照这个思维理解高维数组。不过我还要补充一点,我推荐二维数组的写法是这样,这种写法不影响编译,但能更加直观,对开发者很友好,一眼就能看出行列分布,也能直观看出数组1是{1,2,3}数组2是{4,5,6}
int a[2][3]={
{1,2,3},
{4,5,6}
};现在再回来看文章最顶部的第一个例子应该就很好理解了。
接下来,我们探讨一下用指针访问二维数组
#include <stdio.h>
int main(){
int a[2][3]={
{1,2,3},
{4,5,6},
};
int(*p)[3] = a;
for(int i=0;i<2;i++){
for(int j=0;j<3;j++){
printf("%d ",*(*(p+i)+j));
}
printf("\n");
}
}运行结果
1 2 3
4 5 6
我们采用数组指针来访问二维数组,针对这个表达式,我们来分析一下*(*(p+i)+j) ,首先是*(p+i) ,这里有一点需要补充:
*(p+1)单独使用时表示的是第 1 行数据,放在表达式中会被转换为第 1 行数据的首地址,也就是第 1 行第 0 个元素的地址,因为使用整行数据没有实际的含义,编译器遇到这种情况都会转换为指向该行第 0 个元素的指针;就像一维数组的名字,在定义时或者和 sizeof、& 一起使用时才表示整个数组,出现在表达式中就会被转换为指向数组第 0 个元素的指针。
所以在i为0的时候,我们知道p是指第一行的首地址,如果j为1,那(*(p+0)+1)就是第1行第2个元素的地址,再取引用*(*(p+0)+1)就是第一行第一列的值,同理*(p+1)就是第二行,*(*(p+1)+1)就是第二行第二列的值。
补充
请读者看一下这段代码:
#include <stdio.h>
void fun(int a[]){
int len = sizeof(a);
printf("fun函数中的len的值为%d\n",len);
}
int main(){
int a[3]={1,10,100};
int len = sizeof(a);
printf("main函数中的len的值为%d\n",len);
fun(a);
}这是初学者甚至是大神都可能出现的错误,在我们的预期中,不管是fun函数还是main函数都应该输出12,不过让我们来看一看最终的结果吧:
运行结果
main函数中的len的值为12
fun函数中的len的值为8
是不是感到很不可思议,接下来让我讲解一下,fun(a)中其实传递过去的是a首元素地址,fun(int a[])承接的也是一个首元素的地址,这时的sizeof输出的是指针所占的空间,当然这个和你使用的电脑系统和编译器有关,作者使用的是Linux系统和gcc 9.3.1,所以我们的fun输出的值可能有所不同。
如果我们希望在fun函数中需要用到数组的长度该怎么办,其实这并没有什么好的方法,作者的建议是将fun函数重写,比如改成fun(int a[],int len)长度在主函数中就传过来,这种方法简洁且不易出错。
字符串的隐式与显式赋值
在显式赋值中,比如char a[2] = {'a','b'};通常情况下,编译器是不会在数组末尾自动添加'\0'的。
在隐式赋值中,比如char* a="ab";和char a[]="ab";中,通常情况下,编译器会主动在字符串末尾添加'\0'来作为字符串结束符号。
不过有一点要注意,那就是必须要保证有足够的空间,比如char a[5] = "abcde";由于分配空间不足的原因会导致这个数组即便是隐式赋值的操作,编译器也不会自动加上'\0'
对于多维数组来说也符合这个原则,char a[3][3] = {'a','b','c','d','e','f','g','h','i'};属于显式赋值,不会自动添加'\0'。
但是char a[3][3]={"abc","def","ghi"};隐式赋值因为空间不足的原因也不会自动补充'\0',但是如果是char a[3][4]={"abc","def","ghi"};编译器会为每一行末尾都添加一个'\0',即这个a数组中会存在3个'\0'
不过这个随着平台和编译器的差别可能出现不同的结果,比如在vs2019中,编译器会在char a[3][3]={"abc","def","ghi"}; 报错。
参考链接:C语言中文网
